
 Technology peripherals
AI
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Technology peripherals
AI
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
The paper for Stable Diffusion 3 is finally here!
This model was released two weeks ago and uses the same DiT (Diffusion Transformer) architecture as Sora. It caused quite a stir upon release.
Compared with the previous version, the quality of images generated by Stable Diffusion 3 has been significantly improved. It now supports multi-theme prompts, and the text writing effect has also been improved, and garbled characters no longer appear. Condition.
Stability AI pointed out that Stable Diffusion 3 is a series of models with parameter sizes ranging from 800M to 8B. This parameter range means that the model can be run directly on many portable devices, significantly lowering the threshold for using large AI models.
In a newly released paper, Stability AI said that in human preference-based evaluations, Stable Diffusion 3 outperformed current state-of-the-art text-to-image generation systems such as DALL?E 3. Midjourney v6 and Ideogram v1. Soon, they will make the experimental data, code, and model weights of the study publicly available.
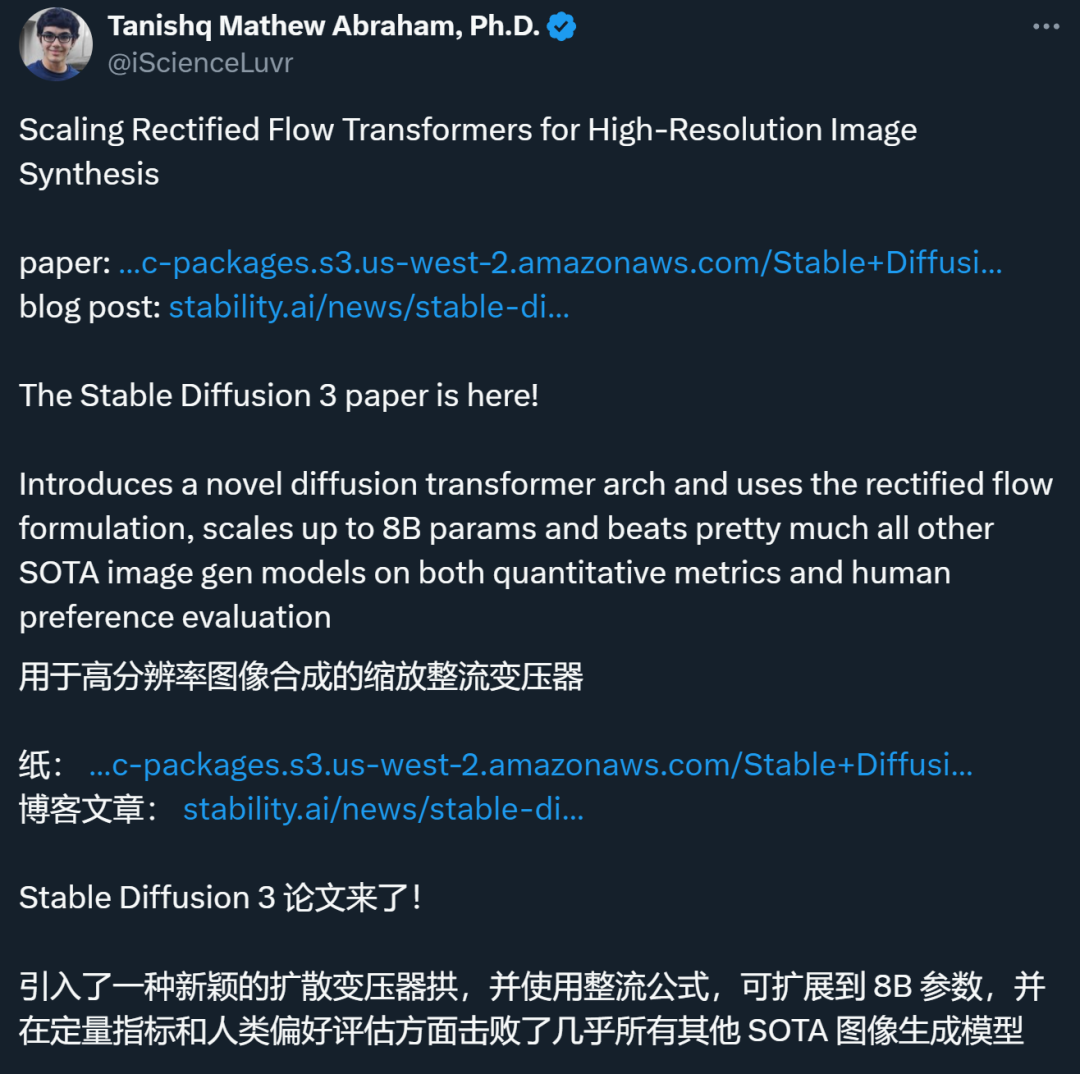
In the paper, Stability AI revealed more details about Stable Diffusion 3.

- ##Paper title: Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
- Paper link: https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable Diffusion 3 Paper.pdf
Architectural details
For text-to-image generation, the Stable Diffusion 3 model must consider both text and image modes. Therefore, the authors of the paper call this new architecture MMDiT, referring to its ability to handle multiple modalities. As with previous versions of Stable Diffusion, the authors use pre-trained models to derive suitable text and image representations. Specifically, they used three different text embedding models—two CLIP models and T5—to encode text representations, and an improved autoencoding model to encode image tokens.
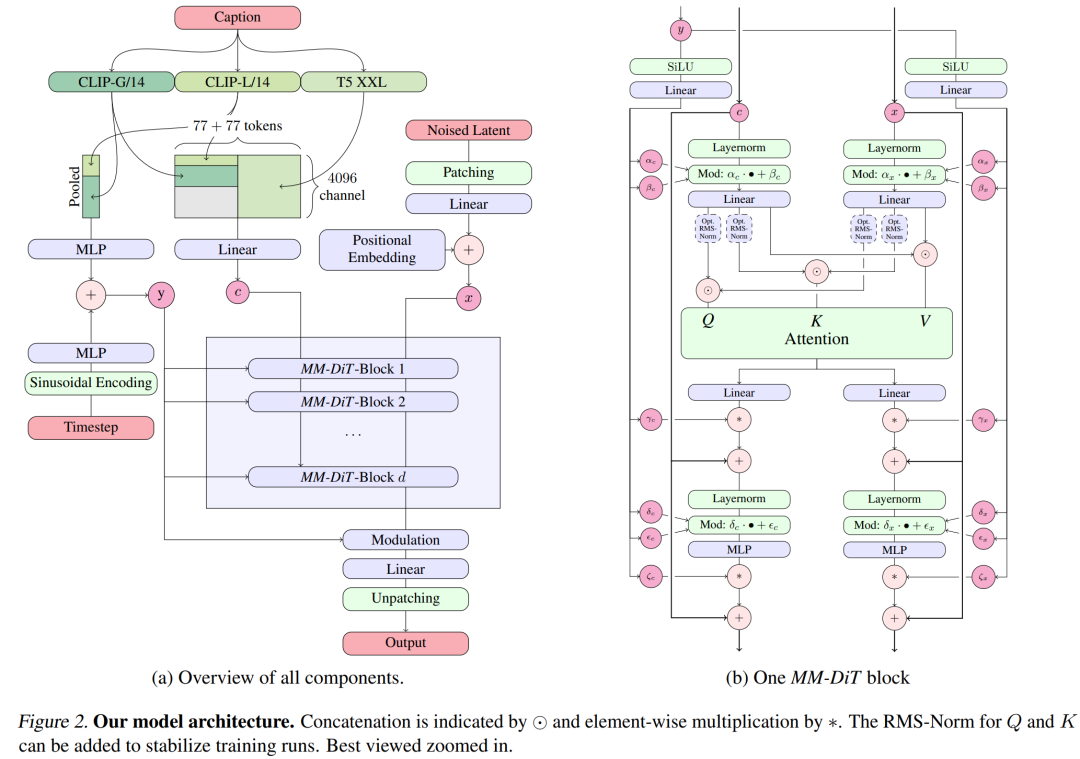
Stable Diffusion 3 model architecture.
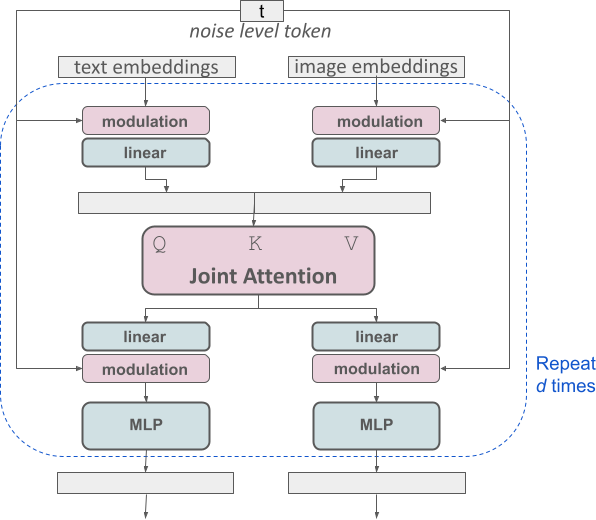
Improved multimodal diffusion transformer: MMDiT block.
The SD3 architecture is based on DiT proposed by Sora core R&D member William Peebles and Xie Saining, assistant professor of computer science at New York University. Since text embedding and image embedding are conceptually very different, the authors of SD3 use two different sets of weights for the two modalities. As shown in the figure above, this is equivalent to setting up two independent transformers for each modality, but combining the sequences of the two modalities for attention operations, so that both representations can work in their own space, Another representation is also taken into account.
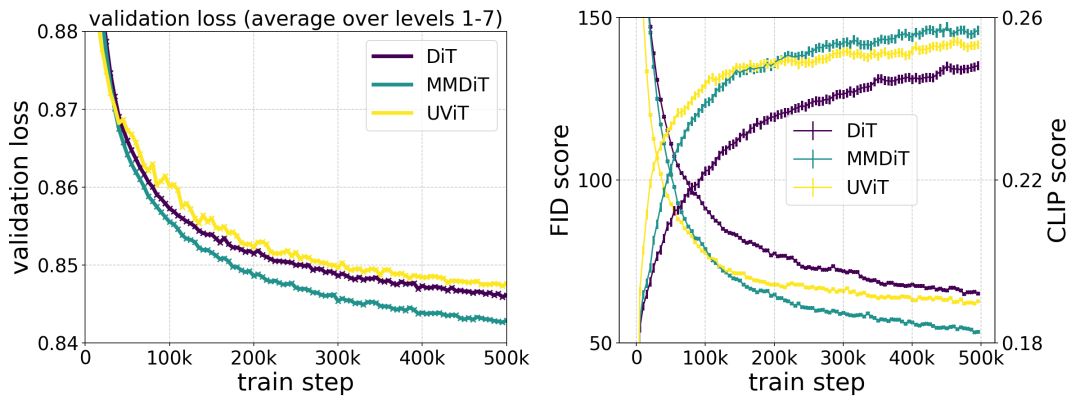
The author's proposed MMDiT architecture outperforms mature textual frameworks such as UViT and DiT when measuring visual fidelity and text alignment during training. to the image backbone.
In this way, information can flow between image and text tokens, thereby improving the overall understanding of the model and improving the typography of the generated output. As discussed in the paper, this architecture is also easily extensible to multiple modalities such as video.

Thanks to Stable Diffusion 3’s improved prompt following capabilities, the new model has the ability to produce images that focus on a variety of different themes and qualities, At the same time, it can also handle the style of the image itself with a high degree of flexibility.

Improve Rectified Flow through re-weighting
Stable Diffusion 3 uses the Rectified Flow (RF) formula. During the training process, Data and noise are connected in a linear trajectory. This makes the inference path straighter, thus reducing sampling steps. In addition, the authors also introduce a new trajectory sampling scheme during the training process. They hypothesized that the middle part of the trajectory would pose a more challenging prediction task, so the scheme gave more weight to the middle part of the trajectory. They compared using multiple datasets, metrics and sampler settings and tested their proposed method against 60 other diffusion trajectories such as LDM, EDM and ADM. The results show that while the performance of previous RF formulations improves with few sampling steps, their relative performance decreases as the number of steps increases. In contrast, the reweighted RF variant proposed by the authors consistently improves performance.
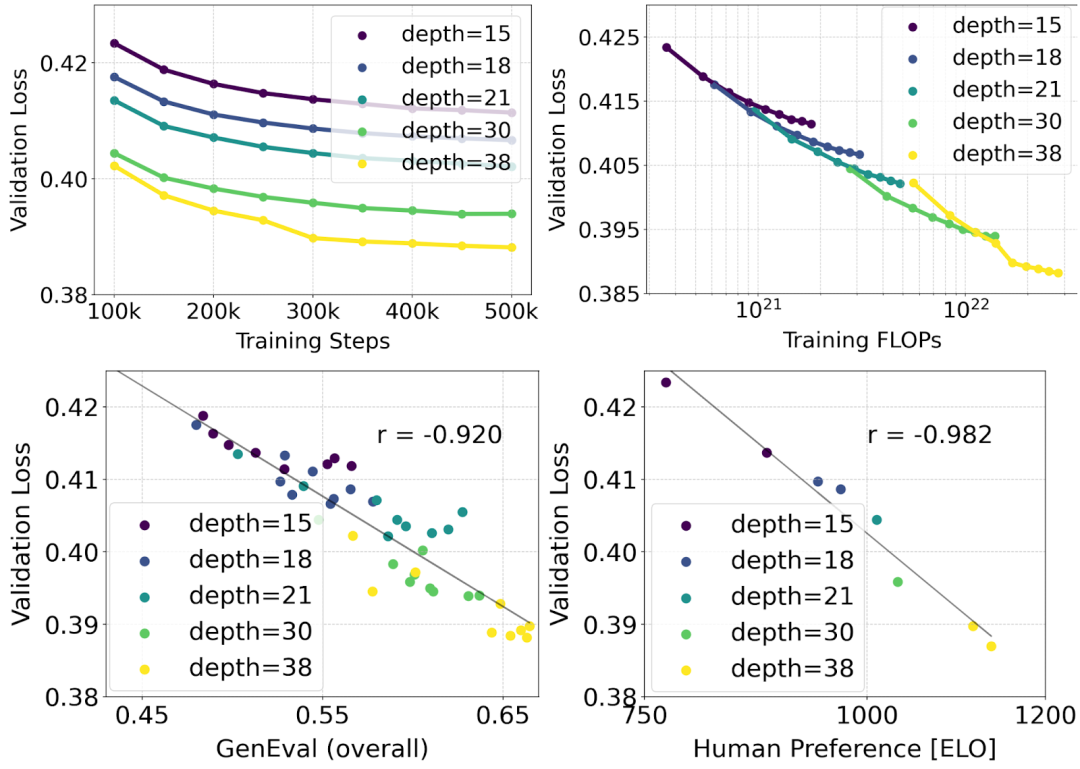
Extended Rectified Flow Transformer model
The author uses the reweighted Rectified Flow formula and MMDiT backbone pair Text-to-image synthesis is studied in scaling. They trained models ranging from 15 blocks with 450M parameters to 38 blocks with 8B parameters and observed that the validation loss decreased smoothly with increasing model size and training steps (first part of the figure above OK). To examine whether this translated into meaningful improvements in model output, the authors also evaluated the automatic image alignment metric (GenEval) and the human preference score (ELO) (second row above). The results show a strong correlation between these metrics and validation loss, suggesting that the latter is a good predictor of the overall performance of the model. Furthermore, the scaling trend shows no signs of saturation, making the authors optimistic about continuing to improve model performance in the future.
Flexible text encoder
By removing memory intensive 4.7B parameter T5 text encoder for inference, SD3 memory Demand can be significantly reduced with minimal performance loss. As shown, removing this text encoder has no impact on visual aesthetics (50% win rate without T5) and only slightly reduces text consistency (46% win rate). However, the authors recommend adding T5 when generating written text to fully utilize the performance of SD3, because they observed that without adding T5, the performance of generating typesetting dropped even more (win rate 38%), as shown in the following figure:

#Removing T5 for inference will only result in a significant decrease in performance when presenting very complex prompts involving many details or large amounts of written text. The image above shows three random samples of each example.
Model performance
The author compared the output image of Stable Diffusion 3 with various other open source models (including SDXL, SDXL Turbo, Stable Cascade, Playground v2.5 and Pixart-α) as well as closed-source models such as DALL-E 3, Midjourney v6 and Ideogram v1 were compared to evaluate performance based on human feedback. In these tests, human evaluators are given examples of output from each model and judged on how well the model output follows the context of the prompt given (prompt following), how well the text is rendered according to the prompt (typography), and which image Images with higher visual aesthetics are selected for the best results.
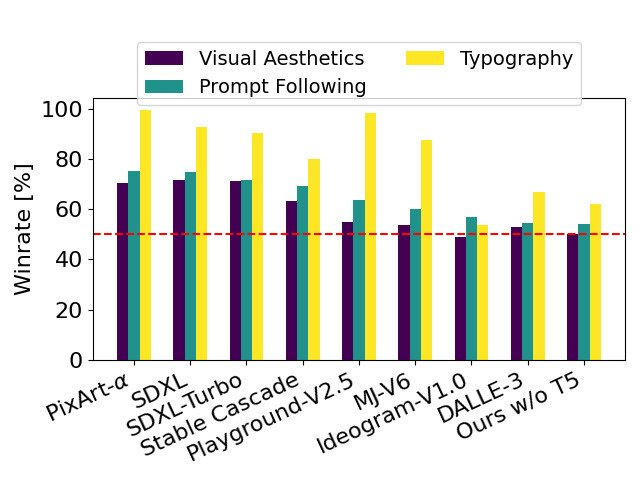
#Using SD3 as the benchmark, this chart outlines its win rate based on human evaluation of visual aesthetics, prompt following, and text layout.
From the test results, the author found that Stable Diffusion 3 is equivalent to or even better than the current state-of-the-art text-to-image generation systems in all the above aspects.
In early unoptimized inference testing on consumer hardware, the largest 8B parameter SD3 model fit the RTX 4090's 24GB VRAM, using 50 sampling steps to generate a resolution of 1024x1024 Image takes 34 seconds.

Additionally, at initial release, Stable Diffusion 3 will be available in multiple variants, ranging from 800m to 8B parametric models to further eliminate hardware barriers.


Please refer to the original paper for more details.
Reference link: https://stability.ai/news/stable-diffusion-3-research-paper
The above is the detailed content of The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)



 PHP calls AI intelligent voice assistant PHP voice interaction system construction
Jul 25, 2025 pm 08:45 PM
PHP calls AI intelligent voice assistant PHP voice interaction system construction
Jul 25, 2025 pm 08:45 PM
User voice input is captured and sent to the PHP backend through the MediaRecorder API of the front-end JavaScript; 2. PHP saves the audio as a temporary file and calls STTAPI (such as Google or Baidu voice recognition) to convert it into text; 3. PHP sends the text to an AI service (such as OpenAIGPT) to obtain intelligent reply; 4. PHP then calls TTSAPI (such as Baidu or Google voice synthesis) to convert the reply to a voice file; 5. PHP streams the voice file back to the front-end to play, completing interaction. The entire process is dominated by PHP to ensure seamless connection between all links.
 How to use PHP to build social sharing functions PHP sharing interface integration practice
Jul 25, 2025 pm 08:51 PM
How to use PHP to build social sharing functions PHP sharing interface integration practice
Jul 25, 2025 pm 08:51 PM
The core method of building social sharing functions in PHP is to dynamically generate sharing links that meet the requirements of each platform. 1. First get the current page or specified URL and article information; 2. Use urlencode to encode the parameters; 3. Splice and generate sharing links according to the protocols of each platform; 4. Display links on the front end for users to click and share; 5. Dynamically generate OG tags on the page to optimize sharing content display; 6. Be sure to escape user input to prevent XSS attacks. This method does not require complex authentication, has low maintenance costs, and is suitable for most content sharing needs.
 How to use PHP combined with AI to achieve text error correction PHP syntax detection and optimization
Jul 25, 2025 pm 08:57 PM
How to use PHP combined with AI to achieve text error correction PHP syntax detection and optimization
Jul 25, 2025 pm 08:57 PM
To realize text error correction and syntax optimization with AI, you need to follow the following steps: 1. Select a suitable AI model or API, such as Baidu, Tencent API or open source NLP library; 2. Call the API through PHP's curl or Guzzle and process the return results; 3. Display error correction information in the application and allow users to choose whether to adopt it; 4. Use php-l and PHP_CodeSniffer for syntax detection and code optimization; 5. Continuously collect feedback and update the model or rules to improve the effect. When choosing AIAPI, focus on evaluating accuracy, response speed, price and support for PHP. Code optimization should follow PSR specifications, use cache reasonably, avoid circular queries, review code regularly, and use X
 PHP realizes commodity inventory management and monetization PHP inventory synchronization and alarm mechanism
Jul 25, 2025 pm 08:30 PM
PHP realizes commodity inventory management and monetization PHP inventory synchronization and alarm mechanism
Jul 25, 2025 pm 08:30 PM
PHP ensures inventory deduction atomicity through database transactions and FORUPDATE row locks to prevent high concurrent overselling; 2. Multi-platform inventory consistency depends on centralized management and event-driven synchronization, combining API/Webhook notifications and message queues to ensure reliable data transmission; 3. The alarm mechanism should set low inventory, zero/negative inventory, unsalable sales, replenishment cycles and abnormal fluctuations strategies in different scenarios, and select DingTalk, SMS or Email Responsible Persons according to the urgency, and the alarm information must be complete and clear to achieve business adaptation and rapid response.
 How to use PHP to call AI writing auxiliary tools PHP improves content output efficiency
Jul 25, 2025 pm 08:18 PM
How to use PHP to call AI writing auxiliary tools PHP improves content output efficiency
Jul 25, 2025 pm 08:18 PM
When choosing an AI writing API, you need to examine stability, price, function matching and whether there is a free trial; 2. PHP uses Guzzle to send POST requests and uses json_decode to process the returned JSON data, pay attention to capturing exceptions and error codes; 3. Integrating AI content into the project requires an audit mechanism and supporting personalized customization; 4. Cache, asynchronous queue and current limiting technology can be used to optimize performance to avoid bottlenecks due to high concurrency.
 The top 10 most authoritative cryptocurrency market websites in the world (the latest version of 2025)
Jul 29, 2025 pm 12:48 PM
The top 10 most authoritative cryptocurrency market websites in the world (the latest version of 2025)
Jul 29, 2025 pm 12:48 PM
The top ten authoritative cryptocurrency market and data analysis platforms in 2025 are: 1. CoinMarketCap, providing comprehensive market capitalization rankings and basic market data; 2. CoinGecko, providing multi-dimensional project evaluation with independence and trust scores; 3. TradingView, having the most professional K-line charts and technical analysis tools; 4. Binance market, providing the most direct real-time data as the largest exchange; 5. Ouyi market, highlighting key derivative indicators such as position volume and capital rate; 6. Glassnode, focusing on on-chain data such as active addresses and giant whale trends; 7. Messari, providing institutional-level research reports and strict standardized data; 8. CryptoCompa
 Twilio call keeping and recovery: Meeting mode with independent call leg processing
Jul 25, 2025 pm 08:42 PM
Twilio call keeping and recovery: Meeting mode with independent call leg processing
Jul 25, 2025 pm 08:42 PM
This article elaborates on two main methods to realize call hold and unhold in Twilio. The preferred option is to leverage Twilio's Conference feature to easily enable call retention and recovery by updating the conference participant resources, and to customize music retention. Another approach is to deal with independent call legs, which requires more complex TwiML logic, passed, and arrived management, but is more cumbersome than meeting mode. The article provides specific code examples and operation steps to help developers efficiently implement Twilio call control.
 What is Ethereum? What are the ways to obtain Ethereum ETH?
Jul 31, 2025 pm 11:00 PM
What is Ethereum? What are the ways to obtain Ethereum ETH?
Jul 31, 2025 pm 11:00 PM
Ethereum is a decentralized application platform based on smart contracts, and its native token ETH can be obtained in a variety of ways. 1. Register an account through centralized platforms such as Binance and Ouyiok, complete KYC certification and purchase ETH with stablecoins; 2. Connect to digital storage through decentralized platforms, and directly exchange ETH with stablecoins or other tokens; 3. Participate in network pledge, and you can choose independent pledge (requires 32 ETH), liquid pledge services or one-click pledge on the centralized platform to obtain rewards; 4. Earn ETH by providing services to Web3 projects, completing tasks or obtaining airdrops. It is recommended that beginners start from mainstream centralized platforms, gradually transition to decentralized methods, and always attach importance to asset security and independent research, to
