
 Technology peripherals
AI
This 'mistake' is not really a mistake: start with four classic papers to understand what is 'wrong' with the Transformer architecture diagram
Technology peripherals
AI
This 'mistake' is not really a mistake: start with four classic papers to understand what is 'wrong' with the Transformer architecture diagram
This 'mistake' is not really a mistake: start with four classic papers to understand what is 'wrong' with the Transformer architecture diagram
Jun 14, 2023 pm 01:43 PM
Some time ago, a tweet pointing out the inconsistency between the Transformer architecture diagram and the code in the Google Brain team's paper "Attention Is All You Need" triggered a lot of discussion.
Some people think that Sebastian’s discovery was an unintentional mistake, but at the same time it is also strange. After all, given the popularity of the Transformer paper, this inconsistency should have been mentioned a thousand times over.
Sebastian Raschka said in response to netizen comments that the "most original" code is indeed consistent with the architecture diagram, but the code version submitted in 2017 was modified, but the architecture was not updated at the same time. picture. This is also the root cause of "inconsistent" discussions.
Subsequently, Sebastian published an article on Ahead of AI specifically describing why the original Transformer architecture diagram was inconsistent with the code, and cited multiple papers to briefly explain the development and changes of Transformer.
##The following is the original text of the article, let us take a look at what the article is about:
A few months ago I shared Understanding Large Language Models: A Cross-Section of the Most Relevant Literature To Get Up to Speed ??and the positive feedback was very encouraging! Therefore, I've added a few papers to keep the list fresh and relevant.
At the same time, it is crucial to keep the list concise and concise so that everyone can get up to speed in a reasonable amount of time. There are also some papers that contain a lot of information and should probably be included.
I would like to share four useful papers to understand Transformer from a historical perspective. While I'm just adding them directly to the Understanding Large Language Models article, I'm also sharing them separately in this article so that they can be more easily found by those who have read Understanding Large Language Models before.
On Layer Normalization in the Transformer Architecture (2020)
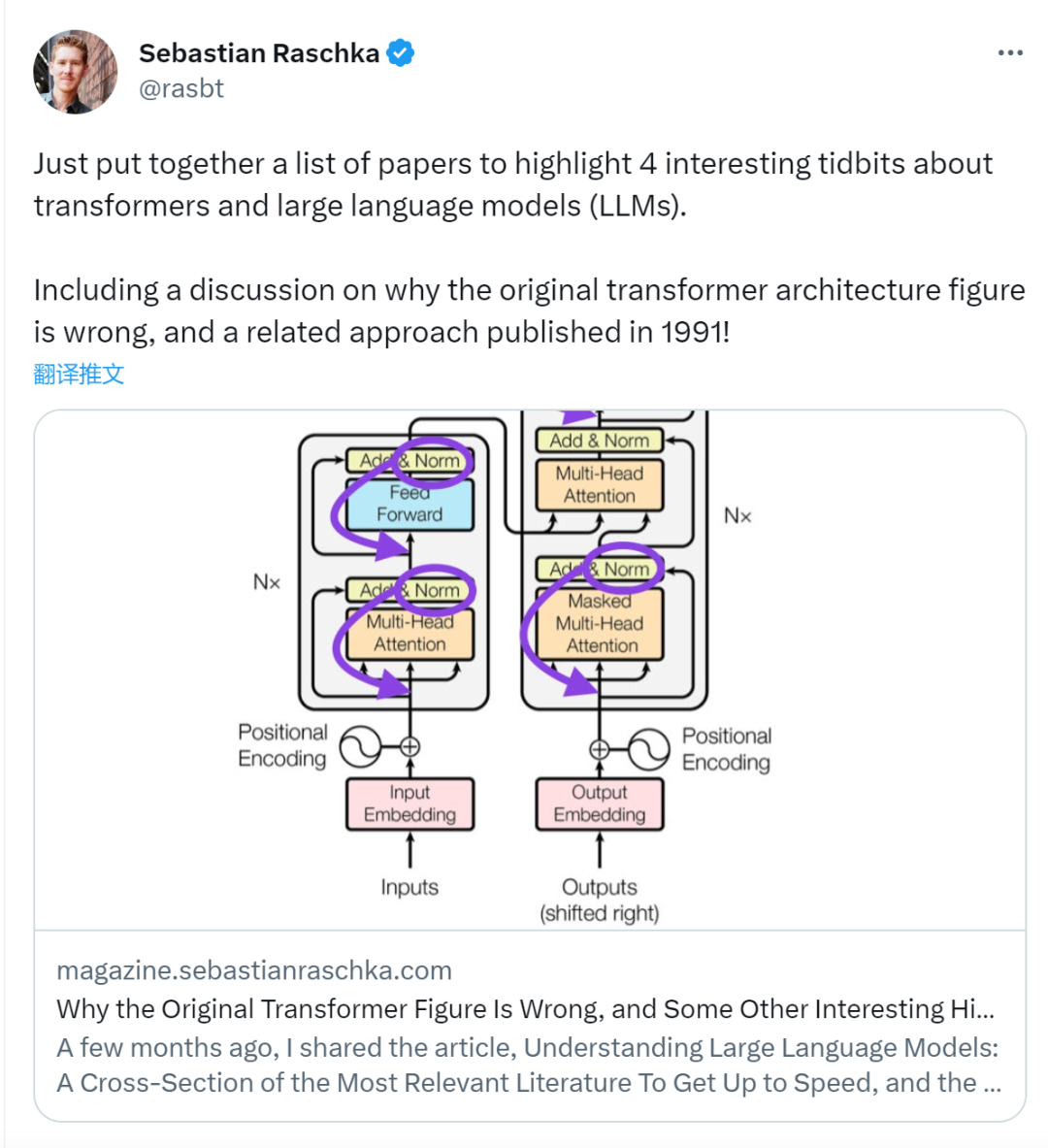
Although the original image of Transformer in the picture below (left) (https://arxiv.org/abs/1706.03762) is a useful summary of the original encoder-decoder architecture, but there is a small difference in the diagram. For example, it does layer normalization between residual blocks, which does not match the official (updated) code implementation included with the original Transformer paper. The variant shown below (middle) is called the Post-LN Transformer.
The layer normalization in the Transformer architecture paper shows that Pre-LN works better and can solve the gradient problem as shown below. Many architectures adopt this approach in practice, but it can lead to a breakdown in representation.
So, while there is still discussion about using Post-LN or Pre-LN, there is also a new paper that proposes applying both together: "ResiDual: Transformer with Dual Residual" Connections" (https://arxiv.org/abs/2304.14802), but whether it will be useful in practice remains to be seen.
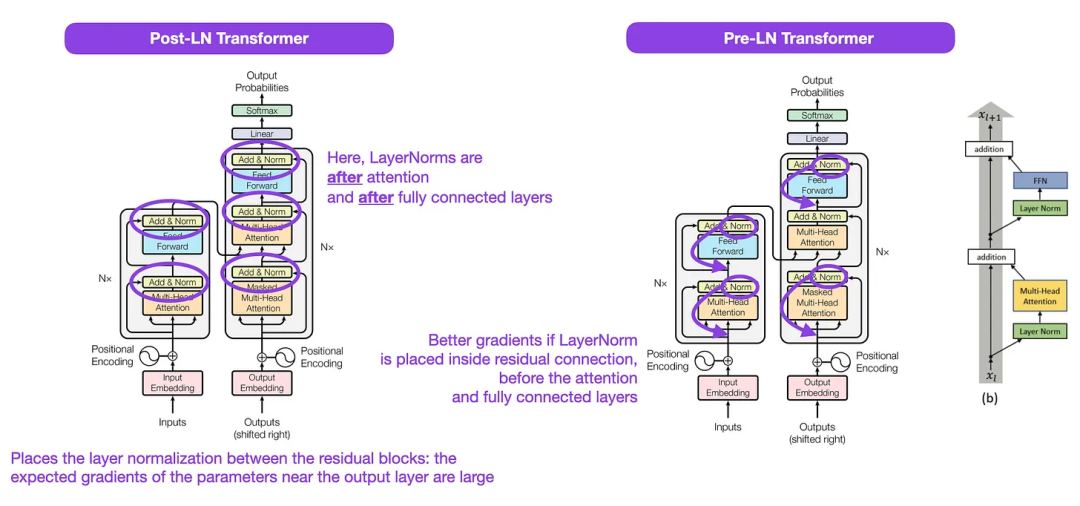
Illustration: Source https://arxiv.org/abs/1706.03762 ( Left & Center) and https://arxiv.org/abs/2002.04745 (Right)
##Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Neural Networks (1991)
This article is recommended for those interested in historical tidbits and early methods that are basically similar to the modern Transformer.For example, in 1991, 25 years before the Transformer paper, Juergen Schmidhuber proposed an alternative to recurrent neural networks (https://www.semanticscholar.org/paper/Learning-to-Control- Fast-Weight-Memories:-An-to-Schmidhuber/bc22e87a26d020215afe91c751e5bdaddd8e4922), called Fast Weight Programmers (FWP). Another neural network that achieves fast weight changes is the feedforward neural network involved in the FWP method that learns slowly using the gradient descent algorithm. This blog (https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2) compares it with a modern Transformer The analogy is as follows: In today's Transformer terminology, FROM and TO are called key and value respectively. The input to which the fast network is applied is called a query. Essentially, queries are handled by a fast weight matrix, which is the sum of the outer products of keys and values ??(ignoring normalization and projection). We can use additive outer products or second-order tensor products to achieve end-to-end differentiable active control of rapid changes in weights because all operations of both networks support differentiation. During sequence processing, gradient descent can be used to quickly adapt fast networks to the problems of slow networks. This is mathematically equivalent to (except for the normalization) what has come to be known as a Transformer with linearized self-attention (or linear Transformer). As mentioned in the excerpt above, this approach is now known as linear Transformer or Transformer with linearized self-attention. They come from the papers "Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention" (https://arxiv.org/abs/2006.16236) and "Rethinking Attention with Performers" (https://arxiv. org/abs/2009.14794). In 2021, the paper "Linear Transformers Are Secretly Fast Weight Programmers" (https://arxiv.org/abs/2102.11174) clearly shows that linearized self-attention and the 1990s Equivalence between fast weight programmers. ##Photo source: https://people.idsia.ch// ~juergen/fast-weight-programmer-1991-transformer.html#sec2 ##Universal Language Model Fine-tuning for Text Classification (2018) ULMFit’s proposed language model fine-tuning process is divided into three stages:
However, as a key part of ULMFiT, progressive unfreezing is usually not performed in practice because Transformer architecture usually fine-tunes all layers at once.
Gopher is a particularly good paper (https://arxiv.org/abs/2112.11446) that includes extensive analysis to understand LLM training. The researchers trained an 80-layer, 280 billion parameter model on 300 billion tokens. This includes some interesting architectural modifications, such as using RMSNorm (root mean square normalization) instead of LayerNorm (layer normalization). Both LayerNorm and RMSNorm are better than BatchNorm because they are not limited to batch size and do not require synchronization, which is an advantage in distributed settings with smaller batch sizes. RMSNorm is generally considered to stabilize training in deeper architectures. Besides the interesting tidbits above, the main focus of this article is to analyze task performance analysis at different scales. An evaluation on 152 different tasks shows that increasing model size is most beneficial for tasks such as comprehension, fact-checking, and identifying toxic language, while architecture expansion is less beneficial for tasks related to logical and mathematical reasoning. ##Illustration: Source https://arxiv.org/abs/2112.11446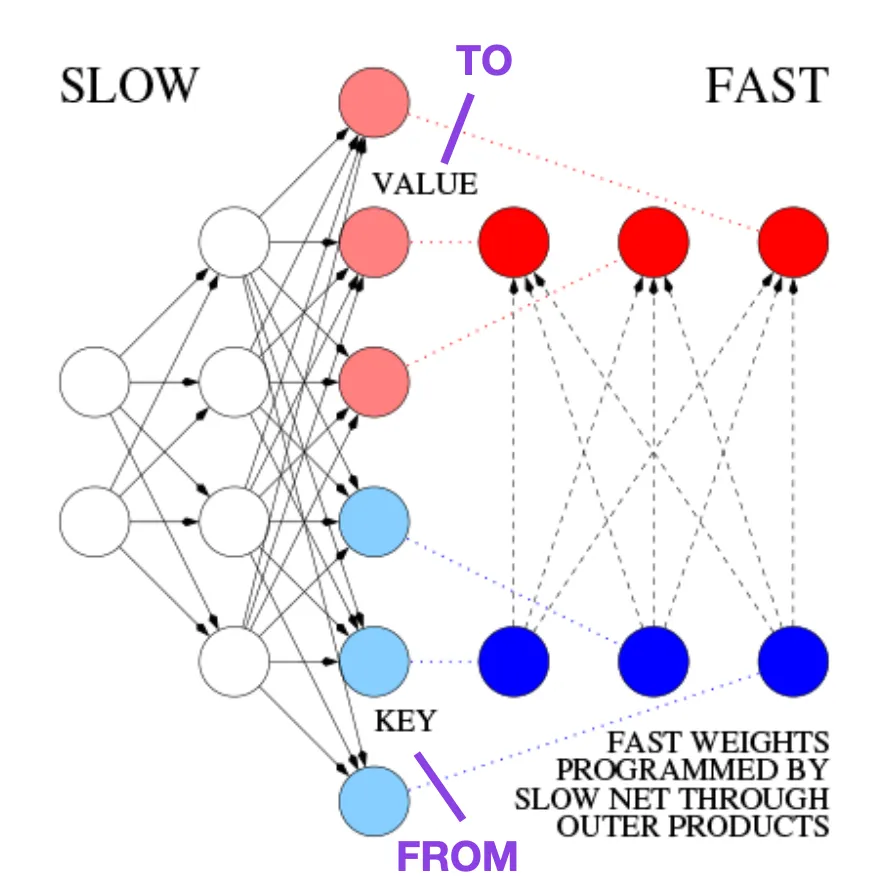
1. Training the language on a large text corpus Model;
This method of training a language model on a large corpus and then fine-tuning it on downstream tasks is based on Transformer models and basic models (such as BERT, GPT -2/3/4, RoBERTa, etc.). 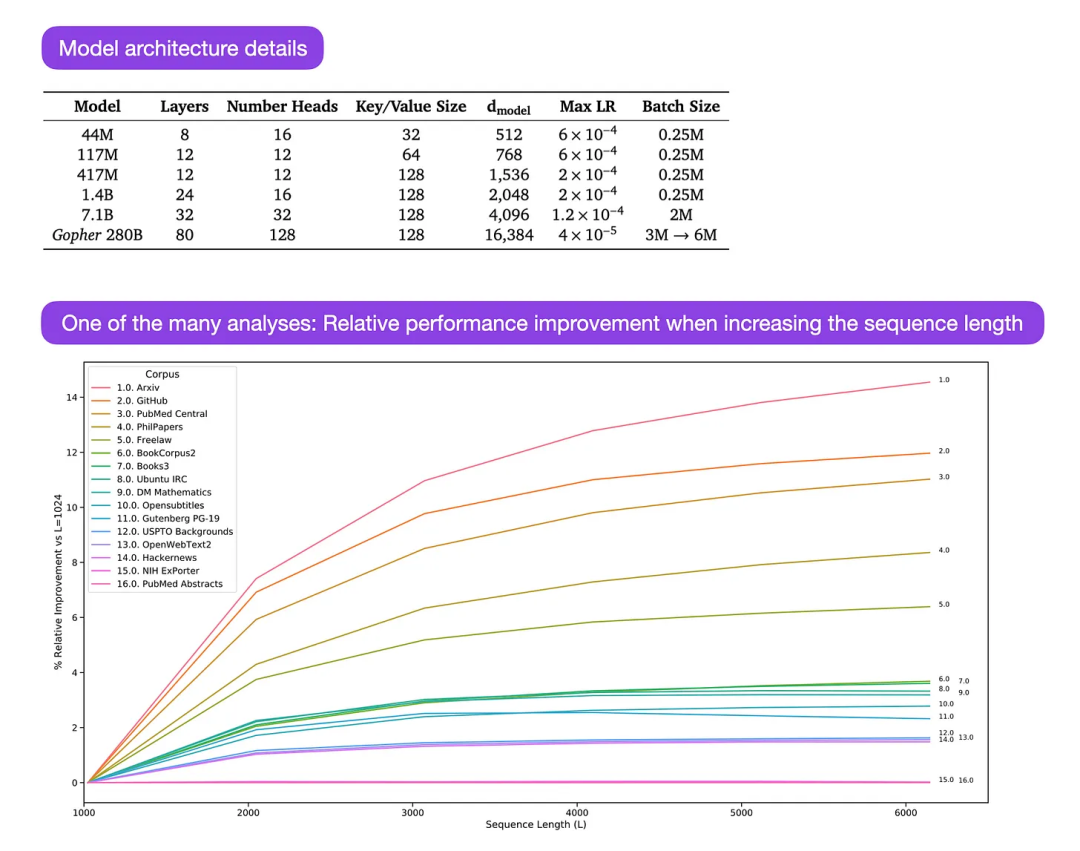
The above is the detailed content of This 'mistake' is not really a mistake: start with four classic papers to understand what is 'wrong' with the Transformer architecture diagram. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)



 How to use PHP to build social sharing functions PHP sharing interface integration practice
Jul 25, 2025 pm 08:51 PM
How to use PHP to build social sharing functions PHP sharing interface integration practice
Jul 25, 2025 pm 08:51 PM
The core method of building social sharing functions in PHP is to dynamically generate sharing links that meet the requirements of each platform. 1. First get the current page or specified URL and article information; 2. Use urlencode to encode the parameters; 3. Splice and generate sharing links according to the protocols of each platform; 4. Display links on the front end for users to click and share; 5. Dynamically generate OG tags on the page to optimize sharing content display; 6. Be sure to escape user input to prevent XSS attacks. This method does not require complex authentication, has low maintenance costs, and is suitable for most content sharing needs.
 PHP calls AI intelligent voice assistant PHP voice interaction system construction
Jul 25, 2025 pm 08:45 PM
PHP calls AI intelligent voice assistant PHP voice interaction system construction
Jul 25, 2025 pm 08:45 PM
User voice input is captured and sent to the PHP backend through the MediaRecorder API of the front-end JavaScript; 2. PHP saves the audio as a temporary file and calls STTAPI (such as Google or Baidu voice recognition) to convert it into text; 3. PHP sends the text to an AI service (such as OpenAIGPT) to obtain intelligent reply; 4. PHP then calls TTSAPI (such as Baidu or Google voice synthesis) to convert the reply to a voice file; 5. PHP streams the voice file back to the front-end to play, completing interaction. The entire process is dominated by PHP to ensure seamless connection between all links.
 How to use PHP combined with AI to achieve text error correction PHP syntax detection and optimization
Jul 25, 2025 pm 08:57 PM
How to use PHP combined with AI to achieve text error correction PHP syntax detection and optimization
Jul 25, 2025 pm 08:57 PM
To realize text error correction and syntax optimization with AI, you need to follow the following steps: 1. Select a suitable AI model or API, such as Baidu, Tencent API or open source NLP library; 2. Call the API through PHP's curl or Guzzle and process the return results; 3. Display error correction information in the application and allow users to choose whether to adopt it; 4. Use php-l and PHP_CodeSniffer for syntax detection and code optimization; 5. Continuously collect feedback and update the model or rules to improve the effect. When choosing AIAPI, focus on evaluating accuracy, response speed, price and support for PHP. Code optimization should follow PSR specifications, use cache reasonably, avoid circular queries, review code regularly, and use X
 PHP realizes commodity inventory management and monetization PHP inventory synchronization and alarm mechanism
Jul 25, 2025 pm 08:30 PM
PHP realizes commodity inventory management and monetization PHP inventory synchronization and alarm mechanism
Jul 25, 2025 pm 08:30 PM
PHP ensures inventory deduction atomicity through database transactions and FORUPDATE row locks to prevent high concurrent overselling; 2. Multi-platform inventory consistency depends on centralized management and event-driven synchronization, combining API/Webhook notifications and message queues to ensure reliable data transmission; 3. The alarm mechanism should set low inventory, zero/negative inventory, unsalable sales, replenishment cycles and abnormal fluctuations strategies in different scenarios, and select DingTalk, SMS or Email Responsible Persons according to the urgency, and the alarm information must be complete and clear to achieve business adaptation and rapid response.
 How to use PHP to combine AI to generate image. PHP automatically generates art works
Jul 25, 2025 pm 07:21 PM
How to use PHP to combine AI to generate image. PHP automatically generates art works
Jul 25, 2025 pm 07:21 PM
PHP does not directly perform AI image processing, but integrates through APIs, because it is good at web development rather than computing-intensive tasks. API integration can achieve professional division of labor, reduce costs, and improve efficiency; 2. Integrating key technologies include using Guzzle or cURL to send HTTP requests, JSON data encoding and decoding, API key security authentication, asynchronous queue processing time-consuming tasks, robust error handling and retry mechanism, image storage and display; 3. Common challenges include API cost out of control, uncontrollable generation results, poor user experience, security risks and difficult data management. The response strategies are setting user quotas and caches, providing propt guidance and multi-picture selection, asynchronous notifications and progress prompts, key environment variable storage and content audit, and cloud storage.
 PHP integrated AI speech recognition and translator PHP meeting record automatic generation solution
Jul 25, 2025 pm 07:06 PM
PHP integrated AI speech recognition and translator PHP meeting record automatic generation solution
Jul 25, 2025 pm 07:06 PM
Select the appropriate AI voice recognition service and integrate PHPSDK; 2. Use PHP to call ffmpeg to convert recordings into API-required formats (such as wav); 3. Upload files to cloud storage and call API asynchronous recognition; 4. Analyze JSON results and organize text using NLP technology; 5. Generate Word or Markdown documents to complete the automation of meeting records. The entire process needs to ensure data encryption, access control and compliance to ensure privacy and security.
 How to build an online customer service robot with PHP. PHP intelligent customer service implementation technology
Jul 25, 2025 pm 06:57 PM
How to build an online customer service robot with PHP. PHP intelligent customer service implementation technology
Jul 25, 2025 pm 06:57 PM
PHP plays the role of connector and brain center in intelligent customer service, responsible for connecting front-end input, database storage and external AI services; 2. When implementing it, it is necessary to build a multi-layer architecture: the front-end receives user messages, the PHP back-end preprocesses and routes requests, first matches the local knowledge base, and misses, call external AI services such as OpenAI or Dialogflow to obtain intelligent reply; 3. Session management is written to MySQL and other databases by PHP to ensure context continuity; 4. Integrated AI services need to use Guzzle to send HTTP requests, safely store APIKeys, and do a good job of error handling and response analysis; 5. Database design must include sessions, messages, knowledge bases, and user tables, reasonably build indexes, ensure security and performance, and support robot memory
 How to use PHP to call AI writing auxiliary tools PHP improves content output efficiency
Jul 25, 2025 pm 08:18 PM
How to use PHP to call AI writing auxiliary tools PHP improves content output efficiency
Jul 25, 2025 pm 08:18 PM
When choosing an AI writing API, you need to examine stability, price, function matching and whether there is a free trial; 2. PHP uses Guzzle to send POST requests and uses json_decode to process the returned JSON data, pay attention to capturing exceptions and error codes; 3. Integrating AI content into the project requires an audit mechanism and supporting personalized customization; 4. Cache, asynchronous queue and current limiting technology can be used to optimize performance to avoid bottlenecks due to high concurrency.
