
 Backend Development
Golang
An in-depth analysis of the reasons why there is a GMP scheduling model in the Go language
Backend Development
Golang
An in-depth analysis of the reasons why there is a GMP scheduling model in the Go language
An in-depth analysis of the reasons why there is a GMP scheduling model in the Go language
Apr 14, 2023 pm 03:26 PM
Why does Go have a GMP scheduling model? The following article will introduce to you the reasons why there is a GMP scheduling model in the Go language. I hope it will be helpful to you!

#The GMP scheduling model is the essence of Go. It reasonably solves the efficiency problem of multi-threaded concurrent scheduling coroutines.
What is GMP
First of all, we must understand what each generation of GMP refers to.
- G: The abbreviation of Goroutine refers to coroutine, which runs on a thread.
- M: The abbreviation of Machine, that is, thead, thread, cyclic scheduling coroutine and execution.
- P: The abbreviation of Processor, refers to the processor, which stores coroutines in local queues and provides available coroutines that are not dormant for threads.
Threads M each hold When a processor P wants to obtain a coroutine, it is first obtained from P, so the GMP model diagram is as follows:
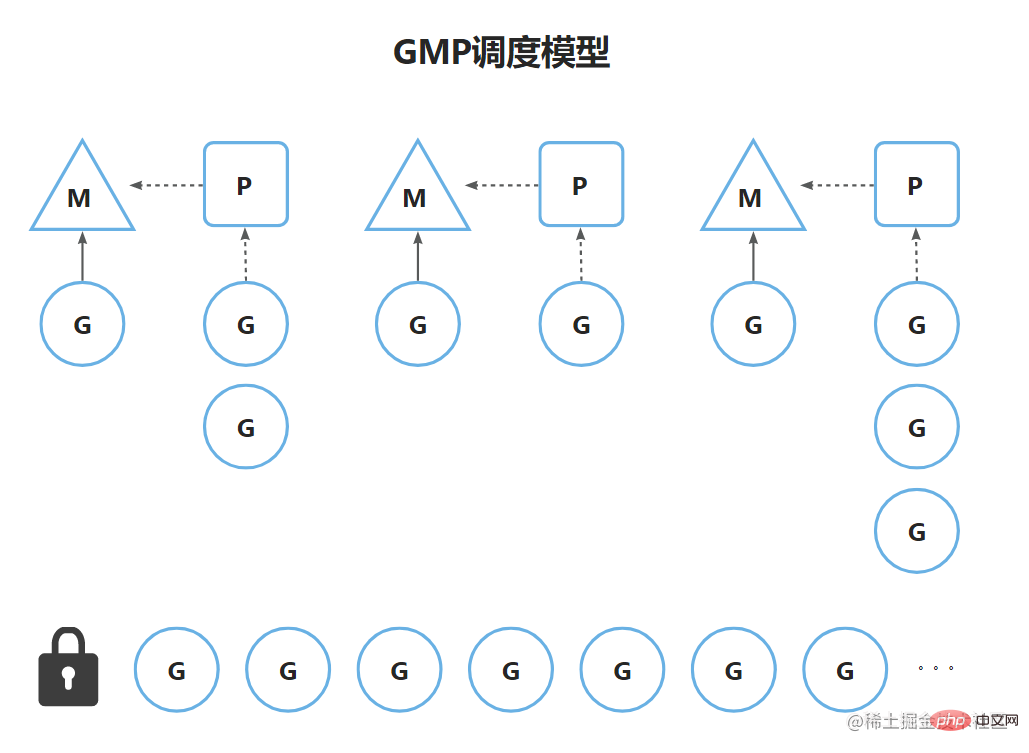
The general process is that thread M obtains it from P's queue If the coroutine cannot obtain it, it will compete for the lock from the global queue to obtain it.
Processor P
The coroutine G and thread M structures have been explained in the previous articles. Here we analyze the processor P.
Function
Processor P stores a batch of coroutines, so that thread M can obtain coroutines from them without locking, without having to compete with other threads for the global queue. Coroutine in the process, thereby improving the efficiency of scheduling coroutines.
Source code analysis
The source code of the p structure is in src\runtime\runtime2.go, and some important fields are shown here.
type p struct {
...
m muintptr // back-link to associated m (nil if idle)
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
runnext guintptr
...
}mis the thread to which the processorpbelongsrunqis a queue that stores coroutinesrunqhead,runqtailrepresents the head and tail pointers of the queuerunnextpoints to the next runnable coroutine
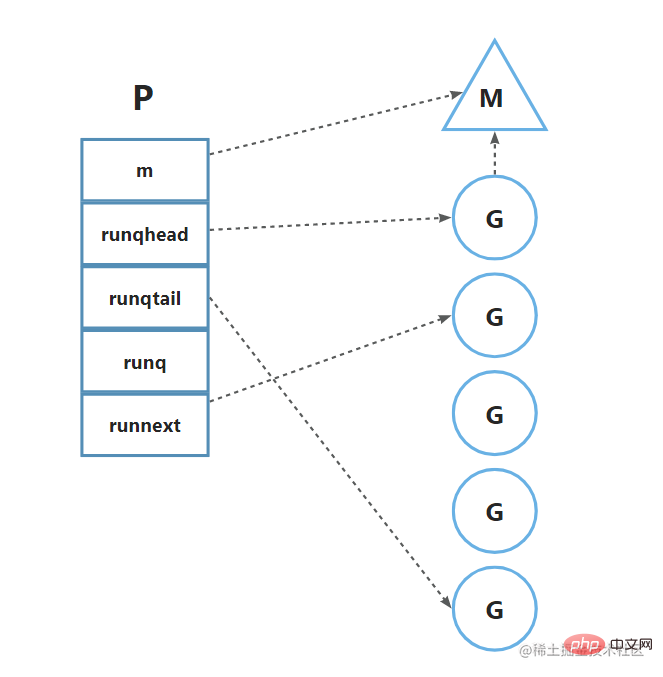
How do thread M and processor P cooperate?
In src\runtime\proc.go, there is a schedule method, which is the first function run by the thread. In this function, the thread needs to obtain a runnable coroutine. The code is as follows:
func schedule() {
...
// 尋找一個(gè)可運(yùn)行的協(xié)程
gp, inheritTime, tryWakeP := findRunnable()
...
}func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
// 從本地隊(duì)列中獲取協(xié)程
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}
// 本地隊(duì)列拿不到則從全局隊(duì)列中獲取協(xié)程
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(pp, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}
}Get the coroutine from the local queue
func runqget(pp *p) (gp *g, inheritTime bool) {
next := pp.runnext // 隊(duì)列中下一個(gè)可運(yùn)行的協(xié)程
if next != 0 && pp.runnext.cas(next, 0) {
return next.ptr(), true
}
...
}If there is no coroutine in the local queue or the global queue What should I do? Should I just let the thread idle like this?
At this time, processor P will steal tasks and steal some tasks from the local queues of other threads. This is called sharing the pressure of other threads and improving the utilization of its own threads.
The source code is in src\runtime\proc.go\stealWork. If you are interested, you can take a look.
Where should the newly created coroutine be allocated?
Should the newly created coroutine be allocated to the local or global queue? Score:
- Go thinks that the new coroutine has a high priority, so it first looks for the local queue to put it in. Enter and jump in line.
- When the queue of this team is full, it will be put into the global queue.
The actual process is:
- Randomly search for P
- Put the new coroutine into P's
runnext, which means The coroutine will be run next and the queue will be jumped. - If P's coroutine is full, it will be put into the global queue
The source code is in src\runtime\proc.go \newproc function.
// Create a new g running fn.
// Put it on the queue of g's waiting to run.
// The compiler turns a go statement into a call to this.
func newproc(fn *funcval) {
gp := getg()
pc := getcallerpc()
systemstack(func() {
newg := newproc1(fn, gp, pc) // 創(chuàng)建新協(xié)程
pp := getg().m.p.ptr()
runqput(pp, newg, true) // 尋找本地隊(duì)列放入
if mainStarted {
wakep()
}
})
}Conclusion
This article initially introduces the GMP scheduling model, and specifically introduces how processor P and thread M obtain coroutines.
Processor P solves the problem of multi-thread mutual exclusion to obtain coroutines and improves the efficiency of scheduling coroutines. However, no matter whether coroutines are in local or global queues, it seems that they are only executed sequentially. So what about Go? How to implement asynchronous and concurrent execution of coroutines? Let’s continue the analysis in the next article (although no one will read it...).
Recommended learning: Golang tutorial
The above is the detailed content of An in-depth analysis of the reasons why there is a GMP scheduling model in the Go language. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How does the switch statement work in Go?
Jul 30, 2025 am 05:11 AM
How does the switch statement work in Go?
Jul 30, 2025 am 05:11 AM
Go's switch statement will not be executed throughout the process by default and will automatically exit after matching the first condition. 1. Switch starts with a keyword and can carry one or no value; 2. Case matches from top to bottom in order, only the first match is run; 3. Multiple conditions can be listed by commas to match the same case; 4. There is no need to manually add break, but can be forced through; 5.default is used for unmatched cases, usually placed at the end.
 how to break from a nested loop in go
Jul 29, 2025 am 01:58 AM
how to break from a nested loop in go
Jul 29, 2025 am 01:58 AM
In Go, to break out of nested loops, you should use labeled break statements or return through functions; 1. Use labeled break: Place the tag before the outer loop, such as OuterLoop:for{...}, use breakOuterLoop in the inner loop to directly exit the outer loop; 2. Put the nested loop into the function, and return in advance when the conditions are met, thereby terminating all loops; 3. Avoid using flag variables or goto, the former is lengthy and easy to make mistakes, and the latter is not recommended; the correct way is that the tag must be before the loop rather than after it, which is the idiomatic way to break out of multi-layer loops in Go.
 Using the Context Package in Go for Cancellation and Timeouts
Jul 29, 2025 am 04:08 AM
Using the Context Package in Go for Cancellation and Timeouts
Jul 29, 2025 am 04:08 AM
Usecontexttopropagatecancellationanddeadlinesacrossgoroutines,enablingcooperativecancellationinHTTPservers,backgroundtasks,andchainedcalls.2.Withcontext.WithCancel(),createacancellablecontextandcallcancel()tosignaltermination,alwaysdeferringcancel()t
 Performance benefits of switching to Go
Jul 28, 2025 am 01:53 AM
Performance benefits of switching to Go
Jul 28, 2025 am 01:53 AM
Gooffersfasterexecutionspeedduetocompilationtonativemachinecode,outperforminginterpretedlanguageslikePythonintaskssuchasservingHTTPrequests.2.Itsefficientconcurrencymodelusinglightweightgoroutinesenablesthousandsofconcurrentoperationswithlowmemoryand
 Building a GraphQL Server in Go
Jul 28, 2025 am 02:10 AM
Building a GraphQL Server in Go
Jul 28, 2025 am 02:10 AM
InitializeaGomodulewithgomodinit,2.InstallgqlgenCLI,3.Defineaschemainschema.graphqls,4.Rungqlgeninittogeneratemodelsandresolvers,5.Implementresolverfunctionsforqueriesandmutations,6.SetupanHTTPserverusingthegeneratedschema,and7.RuntheservertoaccessGr
 Building Performant Go Clients for Third-Party APIs
Jul 30, 2025 am 01:09 AM
Building Performant Go Clients for Third-Party APIs
Jul 30, 2025 am 01:09 AM
Use a dedicated and reasonably configured HTTP client to set timeout and connection pools to improve performance and resource utilization; 2. Implement a retry mechanism with exponential backoff and jitter, only retry for 5xx, network errors and 429 status codes, and comply with Retry-After headers; 3. Use caches for static data such as user information (such as sync.Map or Redis), set reasonable TTL to avoid repeated requests; 4. Use semaphore or rate.Limiter to limit concurrency and request rates to prevent current limit or blocking; 5. Encapsulate the API as an interface to facilitate testing, mocking, and adding logs, tracking and other middleware; 6. Monitor request duration, error rate, status code and retry times through structured logs and indicators, combined with Op
 how to properly copy a slice in go
Jul 30, 2025 am 01:28 AM
how to properly copy a slice in go
Jul 30, 2025 am 01:28 AM
To correctly copy slices in Go, you must create a new underlying array instead of directly assigning values; 1. Use make and copy functions: dst:=make([]T,len(src));copy(dst,src); 2. Use append and nil slices: dst:=append([]T(nil),src...); both methods can realize element-level copying, avoid sharing the underlying array, and ensure that modifications do not affect each other. Direct assignment of dst=src will cause both to refer to the same array and are not real copying.
 Working with Time and Dates in Go
Jul 30, 2025 am 02:51 AM
Working with Time and Dates in Go
Jul 30, 2025 am 02:51 AM
Go uses time.Time structure to process dates and times, 1. Format and parse the reference time "2006-01-0215:04:05" corresponding to "MonJan215:04:05MST2006", 2. Use time.Date(year, month, day, hour, min, sec, nsec, loc) to create the date and specify the time zone such as time.UTC, 3. Time zone processing uses time.LoadLocation to load the position and use time.ParseInLocation to parse the time with time zone, 4. Time operation uses Add, AddDate and Sub methods to add and subtract and calculate the interval.
