


Metadata in Java, defined as the data about the data, is called “Metadata”. Metadata is also said to be documentation about the information required by the users. This is one of the essential aspects in the case of data warehousing.
ADVERTISEMENT Popular Course in this category JAVA MASTERY - Specialization | 78 Course Series | 15 Mock TestsReal-Time Examples: A library catalog, the table of content, data items about person data (person weight, a person walking, etc.), etc.
Metadata Consisting of the following things:
- The description and location of the system and its components.
- It also has the Names, definitions, content, and structures of data and end-user views.
- Identification of authoritative data.
- Integration and transformation rules are used to populate data.
- Subscription information of subscribers.
- Used to analyze data usage and performance.
Why is Metadata Necessary?
It gives the Java developers information about the contents like table data, library catalog, etc., and structures.
Types of Metadata
There are 3 types of metadata:
- Operational Metadata
- Extraction and Transformation Metadata
- End-User Metadata
1. Operational Metadata: Operational metadata has all the information of the operational data sources. While selecting information from the source system for Datawarehouse, we will divide the records, combine the factors of documents from various sources, and deal with multiple coding schemes and field lengths. While we deliver the information to end-users, then we must be able to get back to source data sets.
2. Extraction and Transformation Metadata: Extraction and Transformation Metadata include data about removing data from the source systems. Those extraction methods, frequencies, and business rules for data extraction belong to Extraction and Transformation Metadata.
3. End-User Metadata: The end-user metadata is the navigational map of the data house. It enables the end-users to find the data from the data warehouse.
How does Metadata work in Java?
Java Metadata works based on data provided to it. It gives information of data about the data.
Syntax:
class Metadata{
public static void main(String args[]){
try{
//load required database class
//creating database metadata class
DatabaseMetaData metaData=con.getMetaData();
//display the metadata of the table content
System.out.println(metaData.getDriverName());
System.out.println(metaData.getDriverVersion());
System.out.println(metaData.getUserName());
System.out.println(metaData.getDatabaseProductName());
System.out.println(metaData.getDatabaseProductVersion());
con.close();
}catch(Exception e){ System.out.println(e);}
}
}
Note: Before getting into the example, you must need MySQL database and mysql-connector jar.
Examples to Implement Metadata in Java
Below are examples of Metadata in Java:
Example #1 – Result Set Metadata
?Code:
import java.sql.*;//importing sql package
public class A {//Creating class
//main method for run the application
public static void main(String args[]) {
try {
//loading my sql driver
Class.forName("com.mysql.jdbc.Driver");
//get the connection by providing database, user name and password
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "root");
//select the all from employee table
PreparedStatement preparedStatement = connection.prepareStatement("select * from employee");
//executing the query
ResultSet resultSet = preparedStatement.executeQuery();
//Create result meta data for get the meta data of table
ResultSetMetaData resultSetMetaData = resultSet.getMetaData();
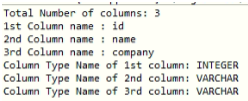
//Displaying meta data of employee table
System.out.println("Total Number of columns: " + resultSetMetaData.getColumnCount());
System.out.println("1st Column name : " + resultSetMetaData.getColumnName(1));
System.out.println("2nd Column name : " + resultSetMetaData.getColumnName(2));
System.out.println("3rd Column name : " + resultSetMetaData.getColumnName(3));
System.out.println("Column Type Name of 1st column: " + resultSetMetaData.getColumnTypeName(1));
System.out.println("Column Type Name of 2nd column: " + resultSetMetaData.getColumnTypeName(2));
System.out.println("Column Type Name of 3rd column: " + resultSetMetaData.getColumnTypeName(3));
connection.close();
} catch (Exception e) {
System.out.println(e);
}
}
}
Output:
Example #2 – Database Metadata
Code:
import java.sql.*;//importing sql package
public class A {//Creating class
//main method for run the application
public static void main(String args[]) {
try {
//loading my sql driver
Class.forName("com.mysql.jdbc.Driver");
//get the connection by providing database, user name and password
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test","root", "root");
//select the all from employee table
PreparedStatement preparedStatement = connection.prepareStatement("select * from employee");
//executing the query
preparedStatement.executeQuery();
//Create databse result set meta data for get the meta data of databse of mysql
DatabaseMetaData databaseMetaData=connection.getMetaData();
//Displaying meta data of mysql table
System.out.println("MYSQL Driver Name: "+databaseMetaData.getDriverName());
System.out.println("MYSQL Driver Version: "+databaseMetaData.getDriverVersion());
System.out.println("MYSQL UserName: "+databaseMetaData.getUserName());
System.out.println("MYSQL Database Product Name:"+databaseMetaData.getDatabaseProductName());
System.out.println("MYSQL Database Product Version: "+databaseMetaData.getDatabaseProductVersion());
connection.close();
} catch (Exception e) {
System.out.println(e);
}
}
}
Output:

Example #3 – Database Metadata for Extracting Table Names
Code:
import java.sql.*;//importing sql package
public class A {// Creating class
// main method for run the application
public static void main(String args[]) {
try {
// loading my sql driver
Class.forName("com.mysql.jdbc.Driver");
// get the connection by providing database, user name and password
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "root");
// Create databse result set meta data for get the meta data of
// databse of mysql
DatabaseMetaData dbmd = connection.getMetaData();
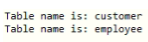
String table[] = { "VIEW" };
ResultSet resultSet = dbmd.getTables(null, null, null, table);
// iterating number table names from database of mysql
while (resultSet.next()) {
System.out.println("Table name is: "+resultSet.getString(3));
}
connection.close();
} catch (Exception e) {
System.out.println(e);
}
}
}
Output:
Conclusion
Metadata in Java is used to know the data about data. It means, for example, table field names, field data type, field data type length, database table names, number of databases that existed in the specific database, etc.
The above is the detailed content of Metadata in Java. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Laravel lazy loading vs eager loading
Jul 28, 2025 am 04:23 AM
Laravel lazy loading vs eager loading
Jul 28, 2025 am 04:23 AM
Lazy loading only queries when accessing associations can easily lead to N 1 problems, which is suitable for scenarios where the associated data is not determined whether it is needed; 2. Emergency loading uses with() to load associated data in advance to avoid N 1 queries, which is suitable for batch processing scenarios; 3. Emergency loading should be used to optimize performance, and N 1 problems can be detected through tools such as LaravelDebugbar, and the $with attribute of the model is carefully used to avoid unnecessary performance overhead.
 Integrating PHP with Machine Learning Models
Jul 28, 2025 am 04:37 AM
Integrating PHP with Machine Learning Models
Jul 28, 2025 am 04:37 AM
UseaRESTAPItobridgePHPandMLmodelsbyrunningthemodelinPythonviaFlaskorFastAPIandcallingitfromPHPusingcURLorGuzzle.2.RunPythonscriptsdirectlyfromPHPusingexec()orshell_exec()forsimple,low-trafficusecases,thoughthisapproachhassecurityandperformancelimitat
 python memory management example
Jul 28, 2025 am 01:10 AM
python memory management example
Jul 28, 2025 am 01:10 AM
Python's memory management is based on reference counting and garbage collection mechanisms. 1. The reference counting mechanism ensures that objects are released immediately when the reference number is 0. The return value of sys.getrefcount() is 1 more than the actual reference because it increases its reference itself; 2. Circular references cannot be cleaned through reference counting, and it depends on the generational recycling of the gc module. Calling gc.collect() can recycle unreachable objects; 3. In actual development, long-term holding of large object references should be avoided. We can use weakref weak references, timely place None to release memory, and use tracemalloc to monitor memory allocation; 4. Summary: Python combines reference counting and garbage collection to manage memory, developers can use tools and optimize reference pipes.
 Laravel raw SQL query example
Jul 29, 2025 am 02:59 AM
Laravel raw SQL query example
Jul 29, 2025 am 02:59 AM
Laravel supports the use of native SQL queries, but parameter binding should be preferred to ensure safety; 1. Use DB::select() to execute SELECT queries with parameter binding to prevent SQL injection; 2. Use DB::update() to perform UPDATE operations and return the number of rows affected; 3. Use DB::insert() to insert data; 4. Use DB::delete() to delete data; 5. Use DB::statement() to execute SQL statements without result sets such as CREATE, ALTER, etc.; 6. It is recommended to use whereRaw, selectRaw and other methods in QueryBuilder to combine native expressions to improve security
 Reactive Programming in Java with Project Reactor and Spring WebFlux
Jul 29, 2025 am 12:04 AM
Reactive Programming in Java with Project Reactor and Spring WebFlux
Jul 29, 2025 am 12:04 AM
Responsive programming implements high concurrency, low latency non-blocking services in Java through ProjectReactor and SpringWebFlux. 1. ProjectReactor provides two core types: Mono and Flux, supports declarative processing of asynchronous data flows, and converts, filters and other operations through operator chains; 2. SpringWebFlux is built on Reactor, supports two programming models: annotation and functional. It runs on non-blocking servers such as Netty, and can efficiently handle a large number of concurrent connections; 3. Using WebFlux Reactor can improve the concurrency capability and resource utilization in I/O-intensive scenarios, and naturally supports SSE and WebSo.
 Notepad find and replace with regex capture groups
Jul 28, 2025 am 02:17 AM
Notepad find and replace with regex capture groups
Jul 28, 2025 am 02:17 AM
Use regular expression capture group in Notepad to effectively reorganize text. First, you need to open the replacement dialog box (Ctrl H), select "Search Mode" as "regular expression", 1. Use () to define the capture group, such as (\w ) to capture words; 2. Use \1 and \2 to reference the corresponding group in the replacement box; 3. Example: Exchange the name "JohnDoe" as "Doe, John", find (\w )\s (\w ), replace it with \2,\1; 4. Date format conversion 2023-12-25 to 25/12/2023, find (\d{4})-(\d{2})-(\d{2}), replace it with \3/\2/\1; 5. Log reordering can extract time, level, ID and other information
 Optimizing Memory Usage in Java Applications
Jul 28, 2025 am 02:40 AM
Optimizing Memory Usage in Java Applications
Jul 28, 2025 am 02:40 AM
UseefficientdatastructureslikeArrayListoverLinkedListandprimitivecollectionstoreduceoverhead;2.Minimizeobjectcreationbyreusingobjects,usingStringBuilderforconcatenation,andcachingexpensiveobjects;3.Preventmemoryleaksbynullifyingreferences,usingstatic
 Using MapStruct for Painless Bean Mapping in Java
Jul 28, 2025 am 03:20 AM
Using MapStruct for Painless Bean Mapping in Java
Jul 28, 2025 am 03:20 AM
MapStruct is a compile-time code generator used to simplify mapping between JavaBeans. 1. It automatically generates implementation classes by defining interfaces to avoid manually writing lengthy set/get mapping code; 2. It has type-safe, no runtime overhead, supports automatic mapping of the same name fields, custom expressions, nested objects and collection mapping; 3. It can be integrated with Spring and uses @Mapper(componentModel="spring") to inject mapper into Springbean; 4. Simple configuration, just introduce mapstruct dependencies and annotationProcessorPaths inserts
