
 Technologie-Peripherieger?te
KI
Konvertieren Sie Textdokumente in eine TF-IDF-Matrix mit TFIDFVectorizer
Technologie-Peripherieger?te
KI
Konvertieren Sie Textdokumente in eine TF-IDF-Matrix mit TFIDFVectorizer
Konvertieren Sie Textdokumente in eine TF-IDF-Matrix mit TFIDFVectorizer
Apr 18, 2025 am 10:26 AM
In diesem Artikel werden die TF-IDF-Technik (Frequenz-Inverse-Dokumentfrequenz) erl?utert, ein entscheidendes Werkzeug in der natürlichen Sprachverarbeitung (NLP) zur Analyse von Textdaten. TF-IDF übertrifft die Einschr?nkungen der Basis-W?rter-Ans?tze, indem sie Begriffe basierend auf ihrer H?ufigkeit innerhalb eines Dokuments und ihrer Seltenheit über eine Sammlung von Dokumenten gewichtet werden. Diese verbesserte Gewichtung verbessert die Textklassifizierung und erh?ht die analytischen F?higkeiten von maschinellen Lernmodellen. Wir werden demonstrieren, wie ein TF-IDF-Modell in Python von Grund auf neu erstellt und numerische Berechnungen durchgeführt werden.
Inhaltsverzeichnis
- Schlüsselbegriffe in TF-IDF
- Term Frequenz (TF) erkl?rt
- Dokumentfrequenz (DF) erl?utert
- Inverse Dokumentfrequenz (IDF) erl?utert
- TF-IDF verstehen
- Numerische TF-IDF-Berechnung
- Schritt 1: Berechnung der Termfrequenz (TF)
- Schritt 2: Berechnung der inversen Dokumentfrequenz (IDF)
- Schritt 3: Berechnung von TF-IDF
- Python-Implementierung mit einem integrierten Datensatz
- Schritt 1: Installation der erforderlichen Bibliotheken
- Schritt 2: Bibliotheken importieren
- Schritt 3: Laden des Datensatzes
- Schritt 4: Initialisieren von
TfidfVectorizer - Schritt 5: Anpassen und Transformieren von Dokumenten
- Schritt 6: Untersuchung der TF-IDF-Matrix untersuchen
- Abschluss
- H?ufig gestellte Fragen
Schlüsselbegriffe in TF-IDF
Definieren wir vor dem Fortfahren die wichtigsten Begriffe:
- T : Begriff (individuelles Wort)
- D : Dokument (eine Reihe von W?rtern)
- N : Gesamtzahl der Dokumente im Korpus
- Corpus : Die gesamte Sammlung von Dokumenten
Term Frequenz (TF) erkl?rt
Die Term Frequenz (TF) quantifiziert, wie oft ein Begriff in einem bestimmten Dokument erscheint. Ein h?herer TF zeigt eine gr??ere Bedeutung in diesem Dokument an. Die Formel lautet:
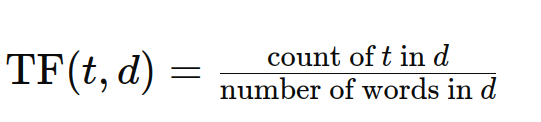
Dokumentfrequenz (DF) erl?utert
Dokumentfrequenz (DF) misst die Anzahl der Dokumente innerhalb des Korpus, der einen bestimmten Term enth?lt. Im Gegensatz zu TF z?hlt es das Vorhandensein eines Begriffs und nicht des Vorkommens. Die Formel lautet:
Df (t) = Anzahl der Dokumente, die Begriff t enthalten
Inverse Dokumentfrequenz (IDF) erl?utert
Die inverse Dokumentfrequenz (IDF) bewertet die Informativit?t eines Wortes. W?hrend TF alle Begriffe gleich behandelt, sind IDF -Abf?lle gemeinsame W?rter (wie Stoppw?rter) und seltenere Begriffe. Die Formel lautet:
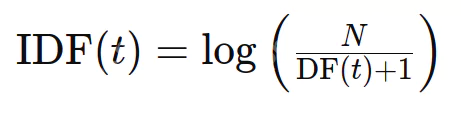
wobei n die Gesamtzahl der Dokumente ist und DF (t) die Anzahl der Dokumente, die Begriff t enthalten.
TF-IDF verstehen
TF-IDF kombiniert Term H?ufigkeit und umgekehrte Dokumentfrequenz, um die Signifikanz eines Begriffs innerhalb eines Dokuments relativ zum gesamten Korpus zu bestimmen. Die Formel lautet:
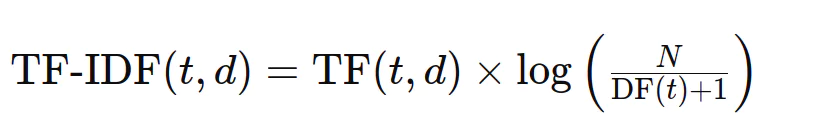
Numerische TF-IDF-Berechnung
Veranschaulichen Sie die numerische TF-IDF-Berechnung mit Beispieldokumenten:
Unterlagen:
- "Der Himmel ist blau."
- "Die Sonne ist heute hell."
- "Die Sonne am Himmel ist hell."
- "Wir k?nnen die leuchtende Sonne sehen, die helle Sonne."
Befolgen Sie die im Originaltext beschriebenen Schritte, wir berechnen TF, IDF und dann TF-IDF für jeden Begriff in jedem Dokument. (Die detaillierten Berechnungen werden hier für die Kürze weggelassen, spiegeln jedoch das ursprüngliche Beispiel wider.)
Python-Implementierung mit einem integrierten Datensatz
In diesem Abschnitt wird die TF-IDF-Berechnung unter Verwendung von TfidfVectorizer von Scikit-Learn und dem 20 Newsgroups-Datensatz angezeigt.
Schritt 1: Installation der erforderlichen Bibliotheken
PIP Installieren Sie Scikit-Learn
Schritt 2: Bibliotheken importieren
Pandas als PD importieren Aus sklearn.datasets importieren Sie Fetch_20newsgroups von sklearn.feature_extraction.text import tfidfVectorizer
Schritt 3: Laden des Datensatzes
Newsgroups = Fetch_20NewsGroups (Subset = 'Train')
Schritt 4: Initialisieren von TfidfVectorizer
vectorizer = tfidfVectorizer (stop_words = 'englisch', max_features = 1000)
Schritt 5: Anpassen und Transformieren von Dokumenten
tfidf_matrix = vectorizer.fit_transform (newsgroups.data)
Schritt 6: Untersuchung der TF-IDF-Matrix untersuchen
df_tfidf = pd.dataframe (tfidf_matrix.toarray (), columns = vectorizer.get_feature_names_out ())) df_tfidf.head ()
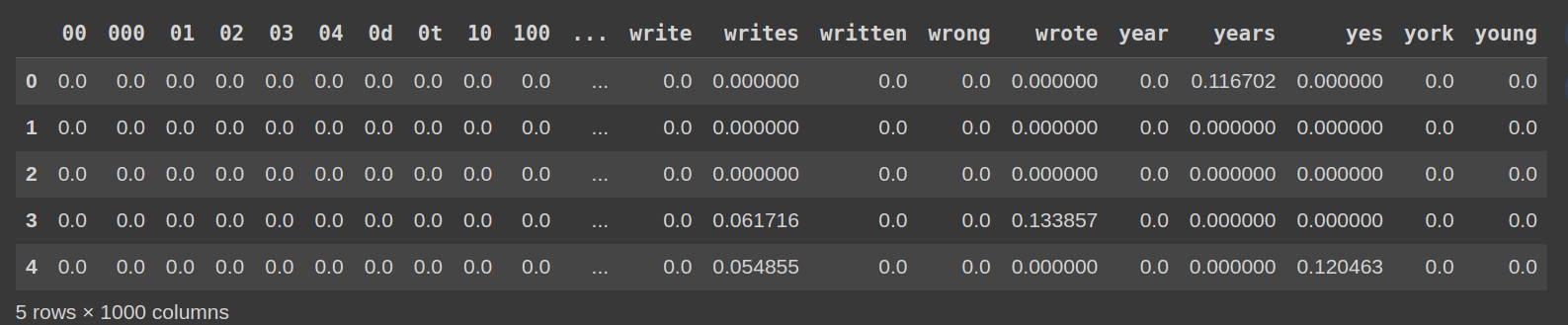
Abschluss
Unter Verwendung des 20 Newsgroups-Datensatzes und TfidfVectorizer transformieren wir Textdokumente effizient in eine TF-IDF-Matrix. Diese Matrix stellt die Bedeutung jedes Begriffs dar und erm?glicht verschiedene NLP -Aufgaben wie die Klassifizierung und Clusterbildung von Text. Der TfidfVectorizer von Scikit-Learn vereinfacht diesen Prozess erheblich.
H?ufig gestellte Fragen
Der FAQS-Abschnitt bleibt weitgehend unver?ndert und adressiert die logarithmische Natur der IDF, die Skalierbarkeit gro?er Datens?tze, Einschr?nkungen von TF-IDF (ignorierende Wortreihenfolge und Kontext ignorieren) und gemeinsame Anwendungen (Suchmaschinen, Textklassifizierung, Clustering, Zusammenfassung).
Das obige ist der detaillierte Inhalt vonKonvertieren Sie Textdokumente in eine TF-IDF-Matrix mit TFIDFVectorizer. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Hei?e KI -Werkzeuge

Undress AI Tool
Ausziehbilder kostenlos

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem v?llig kostenlosen KI-Gesichtstausch-Tool aus!

Hei?er Artikel
Hei?e Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)



 Kimi K2: Das m?chtigste Open-Source-Agentenmodell
Jul 12, 2025 am 09:16 AM
Kimi K2: Das m?chtigste Open-Source-Agentenmodell
Jul 12, 2025 am 09:16 AM
Erinnern Sie sich an die Flut chinesischer Open-Source-Modelle, die die Genai-Industrie Anfang dieses Jahres gest?rt haben? W?hrend Deepseek die meisten Schlagzeilen machte, war Kimi K1.5 einer der herausragenden Namen in der Liste. Und das Modell war ziemlich cool.
 Grok 4 gegen Claude 4: Was ist besser?
Jul 12, 2025 am 09:37 AM
Grok 4 gegen Claude 4: Was ist besser?
Jul 12, 2025 am 09:37 AM
Bis Mitte 2025 heizt sich das KI ?Wettret“ auf, und Xai und Anthropic haben beide ihre Flaggschiff-Modelle GROK 4 und Claude 4 ver?ffentlicht. Diese beiden Modelle befinden
 10 erstaunliche humanoide Roboter, die heute bereits unter uns gehen
Jul 16, 2025 am 11:12 AM
10 erstaunliche humanoide Roboter, die heute bereits unter uns gehen
Jul 16, 2025 am 11:12 AM
Aber wir müssen wahrscheinlich nicht einmal 10 Jahre warten, um einen zu sehen. Was als erste Welle wirklich nützlicher, menschlicher Maschinen angesehen werden k?nnte, ist bereits da. In den letzten Jahren wurden eine Reihe von Prototypen und Produktionsmodellen aus t herausgezogen
 Context Engineering ist der neue ' Schnelltechnik
Jul 12, 2025 am 09:33 AM
Context Engineering ist der neue ' Schnelltechnik
Jul 12, 2025 am 09:33 AM
Bis zum Vorjahr wurde eine schnelle Engineering als entscheidende F?higkeit zur Interaktion mit gro?artigen Modellen (LLMs) angesehen. In jüngster Zeit sind LLM jedoch in ihren Argumentations- und Verst?ndnisf?higkeiten erheblich fortgeschritten. Natürlich unsere Erwartung
 6 Aufgaben Manus ai kann in wenigen Minuten erledigen
Jul 06, 2025 am 09:29 AM
6 Aufgaben Manus ai kann in wenigen Minuten erledigen
Jul 06, 2025 am 09:29 AM
Ich bin sicher, Sie müssen über den allgemeinen KI -Agenten Manus wissen. Es wurde vor einigen Monaten auf den Markt gebracht, und im Laufe der Monate haben sie ihrem System mehrere neue Funktionen hinzugefügt. Jetzt k?nnen Sie Videos erstellen, Websites erstellen und viel MO machen
 Bauen Sie einen Langchain -Fitnesstrainer: Ihr KI -Personal Trainer
Jul 05, 2025 am 09:06 AM
Bauen Sie einen Langchain -Fitnesstrainer: Ihr KI -Personal Trainer
Jul 05, 2025 am 09:06 AM
Viele Menschen haben leidenschaftlich ins Fitnessstudio gegangen und glauben, dass sie auf dem richtigen Weg sind, um ihre Fitnessziele zu erreichen. Die Ergebnisse sind jedoch nicht aufgrund schlechter Di?tplanung und mangelnder Richtung vorhanden. Einstellung eines Personal Trainer Al
 Leia's Imgsitary Mobile App bringt die 3D -Tiefe in allt?gliche Fotos
Jul 09, 2025 am 11:17 AM
Leia's Imgsitary Mobile App bringt die 3D -Tiefe in allt?gliche Fotos
Jul 09, 2025 am 11:17 AM
Aufgebaut auf Leia's propriet?rer neuronaler Tiefenmotor verarbeitet die App still Bilder und fügt die natürliche Tiefe zusammen mit simulierten Bewegungen hinzu - wie Pfannen, Zoome und Parallaxeffekte -, um kurze Video -Rollen zu erstellen, die den Eindruck erwecken, in die SCE einzusteigen
 Diese KI -Modelle haben nicht die Sprache gelernt, sie lernten Strategie
Jul 09, 2025 am 11:16 AM
Diese KI -Modelle haben nicht die Sprache gelernt, sie lernten Strategie
Jul 09, 2025 am 11:16 AM
Eine neue Studie von Forschern am King's College London und der University of Oxford teilt die Ergebnisse dessen, was passiert ist, als OpenAI, Google und Anthropic in einem Cutthroat -Wettbewerb zusammengeworfen wurden, der auf dem iterierten Dilemma des Gefangenen basiert. Das war nein
