


Explication détaillée de la structure des données: du tableau à l'arbre, puis à la table de hachage
Cet article traite de plusieurs structures de données communes en profondeur, notamment des tableaux, des listes liées, des arbres de recherche binaires (BST) et des tables de hachage, et explique leur organisation en mémoire et leurs avantages et inconvénients.
Structure d'information et structure de données abstraite
La structure de l'information fait référence à la fa?on dont les informations sont organisées en mémoire, tandis que les structures de données abstraites sont notre compréhension conceptuelle de ces structures. Comprendre les structures de données abstraites nous aide à mieux mettre en ?uvre diverses structures de données dans la pratique.
Pile et file d'attente
Les files d'attente sont une structure de données abstraite qui suit le principe FIFO (premier dans, premier sorti), similaire à l'attente en ligne. Ses principales opérations incluent la mise en file d'attente (ajoutant des éléments à la queue de la file d'attente) et la désactivation (en supprimant les éléments de la tête de la file d'attente).
La pile suit le principe LIFO (dernier dans le premier sortie), tout comme l'empilement d'une plaque. Ses opérations incluent la poussée (ajoutant des éléments au sommet de la pile) et en retirant les éléments supérieurs de la pile).
Tableau
Un tableau est une structure qui stocke en continu les données en mémoire. Comme le montre la figure ci-dessous, les tableaux occupent l'espace de stockage continu en mémoire.
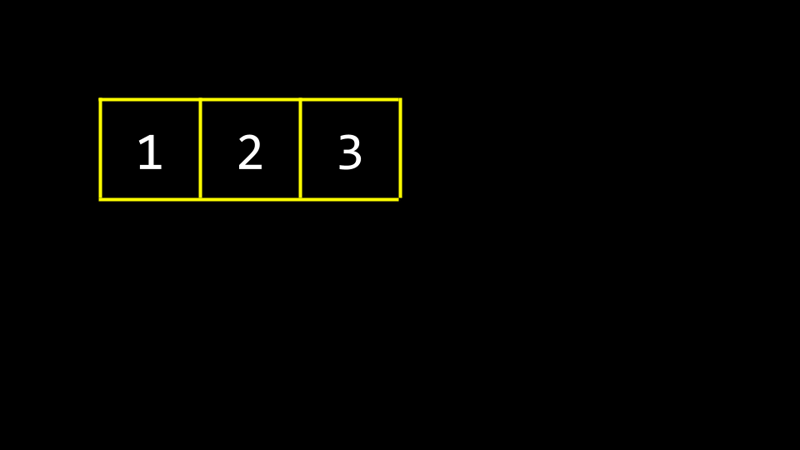
D'autres programmes, fonctions et variables peuvent exister en mémoire, ainsi que des données redondantes qui ont été utilisées auparavant. Si vous devez ajouter de nouveaux éléments au tableau, vous devez réaffecter la mémoire et copier l'intégralité du tableau, qui peut être inefficace.


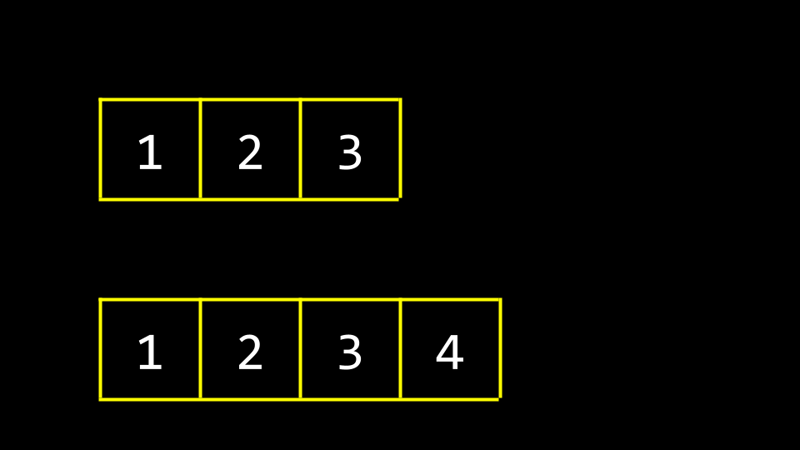
Bien que la pré-allocation de trop de mémoire puisse réduire les opérations de copie, elle gaspillera les ressources du système. Par conséquent, il est crucial d'allouer la mémoire en fonction des besoins réels.
Liste de liens
Les listes liées sont de puissantes structures de données qui permettent la concaténation des valeurs situées dans différentes régions de mémoire dans une liste et prennent en charge l'expansion ou la réduction dynamique.
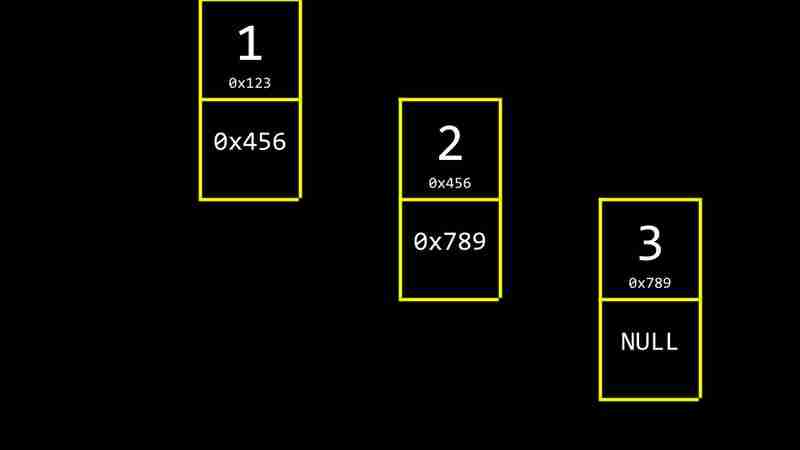
Chaque CS- semaine 5 contient deux valeurs: la valeur de données et un pointeur vers le CS- semaine 5 suivant. La valeur du pointeur du dernier CS- semaine 5 est nul, indiquant la fin de la liste liée.
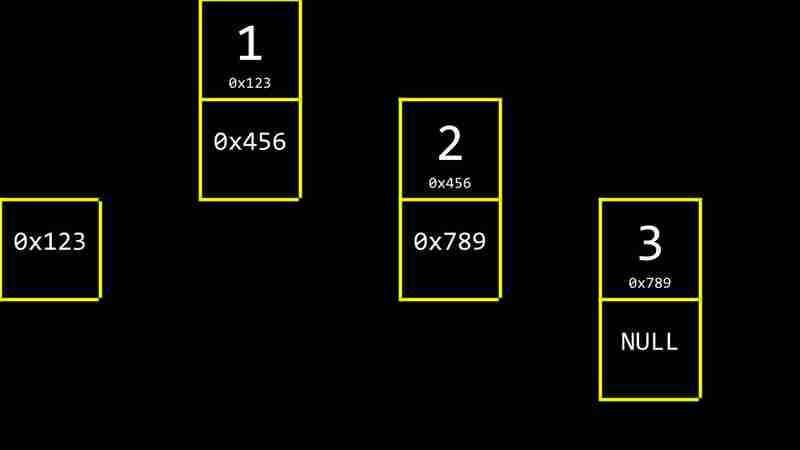
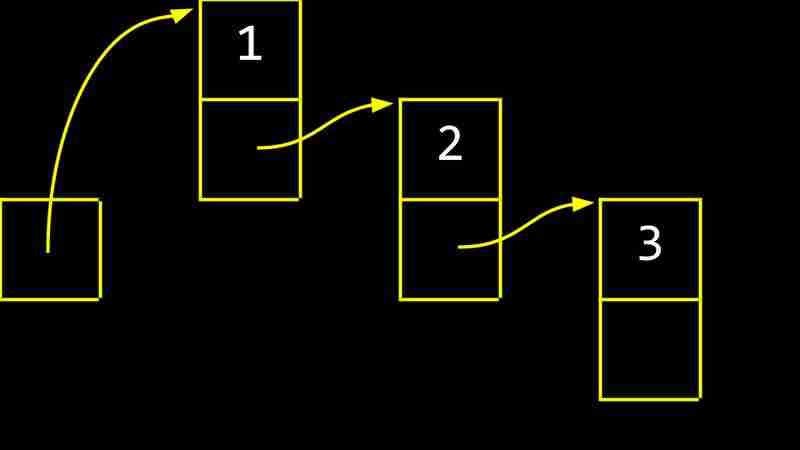
En langue C, les CS- semaine 5s peuvent être définis comme suit:
<code class="c">typedef struct node { int number; struct node *next; } node;</code>
L'exemple suivant montre le processus de création d'une liste liée:

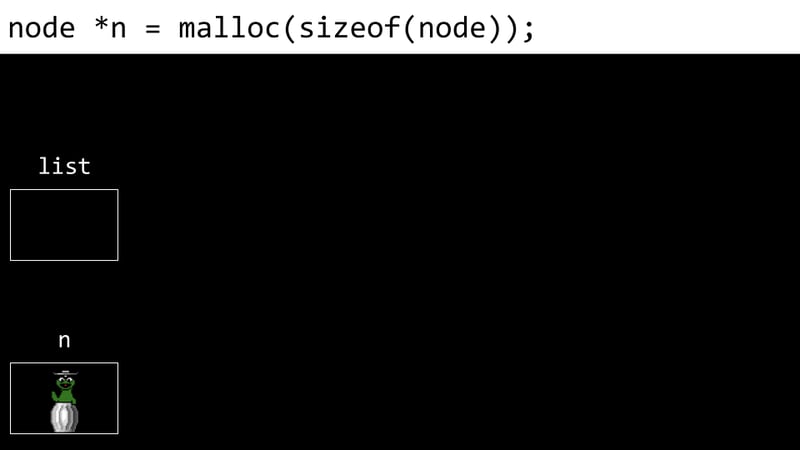

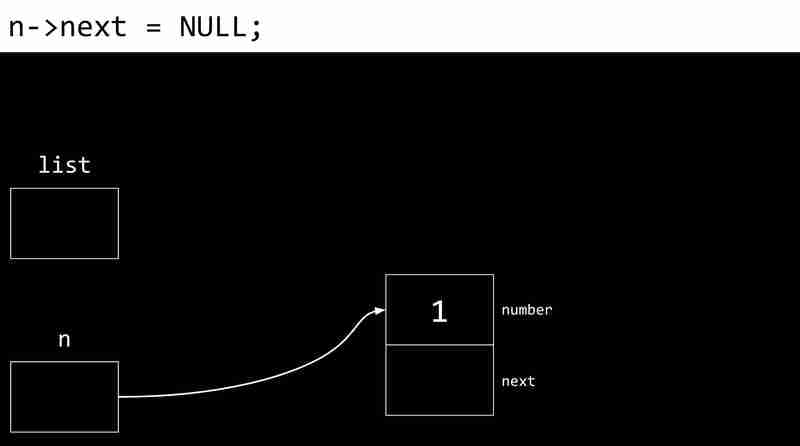
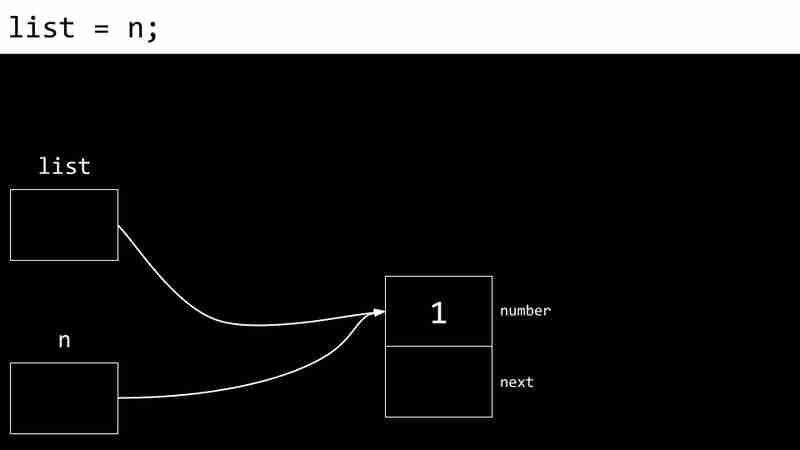
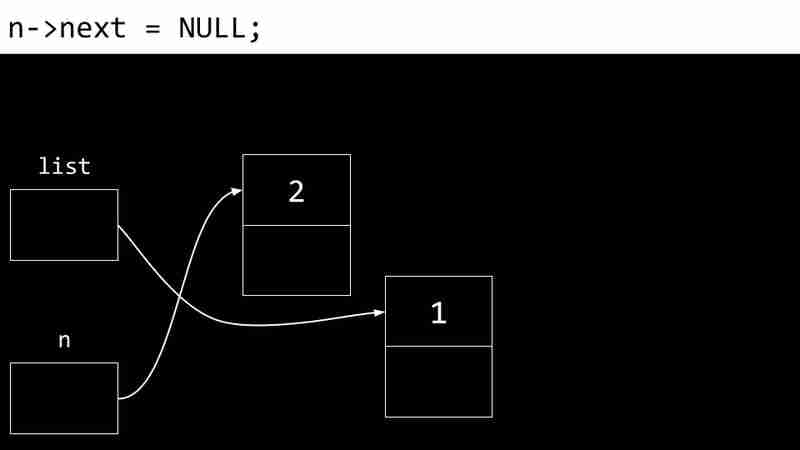
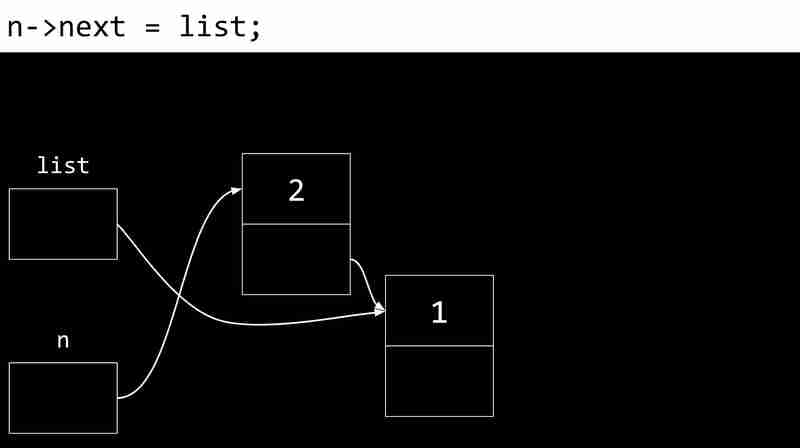

Les inconvénients des listes liées incluent la nécessité de pointeurs de stockage de mémoire supplémentaires et l'incapacité d'accès directement aux éléments via des index.
Arbre de recherche binaire (BST)
Un arbre de recherche binaire est une structure d'arbre qui stocke, recherche et récupère efficacement les données.

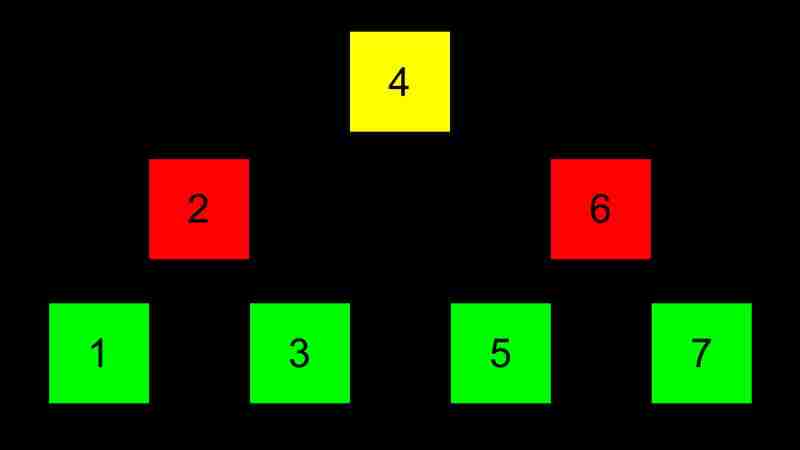
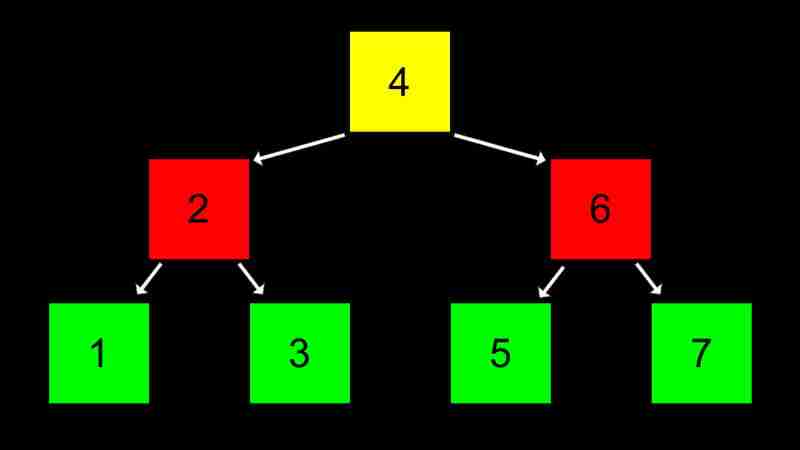
Les avantages de BST sont dynamiques et l'efficacité de recherche (O (log n)), et l'inconvénient est que l'efficacité de recherche tombe à O (n) lorsque l'arbre est déséquilibré et nécessite des pointeurs de stockage de mémoire supplémentaires.
Table de hachage
Une table de hachage est similaire à un dictionnaire et contient des paires de valeurs clés. Il utilise une fonction de hachage pour cartographier les clés pour les indices de tableau, réalisant ainsi le temps de recherche moyen de O (1).

Les conflits de hachage (plusieurs clés mappés au même indice) peuvent être résolus par des listes liées ou d'autres méthodes. La conception des fonctions de hachage est cruciale pour les performances des tables de hachage. Un exemple de fonction de hachage simple est le suivant:
<code class="c">#include <ctype.h> unsigned int hash(const char *word) { return toupper(word[0]) - 'A'; }</ctype.h></code>
Cet article est compilé sur la base du code source CS50X 2024.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
échangez les visages dans n'importe quelle vidéo sans effort grace à notre outil d'échange de visage AI entièrement gratuit?!

Article chaud
Outils chauds

Bloc-notes++7.3.1
éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Comment implémenter Redis Counter
Apr 10, 2025 pm 10:21 PM
Comment implémenter Redis Counter
Apr 10, 2025 pm 10:21 PM
Redis Counter est un mécanisme qui utilise le stockage de la paire de valeurs de clés Redis pour implémenter les opérations de comptage, y compris les étapes suivantes: création de clés de comptoir, augmentation du nombre, diminution du nombre, réinitialisation du nombre et objet de comptes. Les avantages des compteurs Redis comprennent une vitesse rapide, une concurrence élevée, une durabilité et une simplicité et une facilité d'utilisation. Il peut être utilisé dans des scénarios tels que le comptage d'accès aux utilisateurs, le suivi des métriques en temps réel, les scores de jeu et les classements et le comptage de traitement des commandes.
 Comment comprendre la compatibilité ABI en C?
Apr 28, 2025 pm 10:12 PM
Comment comprendre la compatibilité ABI en C?
Apr 28, 2025 pm 10:12 PM
La compatibilité ABI en C se réfère si le code binaire généré par différents compilateurs ou versions peut être compatible sans recompilation. 1. Fonction Calling Conventions, 2. Modification du nom, 3. Disposition de la table de fonction virtuelle, 4. Structure et mise en page de classe sont les principaux aspects impliqués.
 Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
Comment utiliser la commande redis
Apr 10, 2025 pm 08:45 PM
L'utilisation de la directive Redis nécessite les étapes suivantes: Ouvrez le client Redis. Entrez la commande (Verbe Key Value). Fournit les paramètres requis (varie de l'instruction à l'instruction). Appuyez sur Entrée pour exécuter la commande. Redis renvoie une réponse indiquant le résultat de l'opération (généralement OK ou -err).
 Comment formater JSON dans le bloc-notes
Apr 16, 2025 pm 07:48 PM
Comment formater JSON dans le bloc-notes
Apr 16, 2025 pm 07:48 PM
Utilisez le plug-in JSON Viewer dans le bloc-notes pour formater facilement les fichiers JSON: ouvrez un fichier JSON. Installez et activez le plug-in JSON Viewer. Allez dans "Plugins" & gt; "JSON Viewer" & GT; "Format JSON". Personnalisez les paramètres d'indentation, de branchement et de tri. Appliquer le formatage pour améliorer la lisibilité et la compréhension, simplifiant ainsi le traitement et l'édition des données JSON.
 Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
Comment utiliser Redis Lock
Apr 10, 2025 pm 08:39 PM
L'utilisation des opérations Redis pour verrouiller nécessite l'obtention du verrouillage via la commande setnx, puis en utilisant la commande Expire pour définir le temps d'expiration. Les étapes spécifiques sont les suivantes: (1) Utilisez la commande setnx pour essayer de définir une paire de valeurs de clé; (2) Utilisez la commande Expire pour définir le temps d'expiration du verrou; (3) Utilisez la commande del pour supprimer le verrouillage lorsque le verrouillage n'est plus nécessaire.
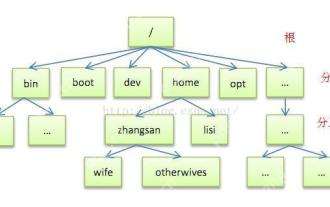 Introduction détaillée à chaque répertoire de Linux et de chaque répertoire (réimprimé)
May 22, 2025 pm 07:54 PM
Introduction détaillée à chaque répertoire de Linux et de chaque répertoire (réimprimé)
May 22, 2025 pm 07:54 PM
[DESCRIPTION DU RéPERTOIRE COMMUN] DIRECTEUR / BIN STORES Fichiers exécutables (LS, CAT, MKDIR, etc.), et les commandes communes sont généralement là. / ETC stocke la gestion du système et les fichiers de configuration / Home Stores tous les fichiers utilisateur. Le répertoire racine du répertoire personnel de l'utilisateur est la base du répertoire domestique de l'utilisateur. Par exemple, le répertoire domestique de l'utilisateur d'utilisateur est / home / utilisateur. Vous pouvez utiliser ~ User pour représenter / USR pour stocker les applications système. Le répertoire plus important / USR / répertoire d'installation du logiciel d'administrateur système local local (installer les applications au niveau du système). Il s'agit du plus grand répertoire, et presque toutes les applications et fichiers à utiliser sont dans ce répertoire. / USR / X11R6 Répertoire pour stocker x fenêtre / usr / bin beaucoup
 Comment gérer la fragmentation de la mémoire redis?
Apr 10, 2025 pm 02:24 PM
Comment gérer la fragmentation de la mémoire redis?
Apr 10, 2025 pm 02:24 PM
La fragmentation de la mémoire redis fait référence à l'existence de petites zones libres dans la mémoire allouée qui ne peut pas être réaffectée. Les stratégies d'adaptation comprennent: Redémarrer Redis: effacer complètement la mémoire, mais le service d'interruption. Optimiser les structures de données: utilisez une structure plus adaptée à Redis pour réduire le nombre d'allocations et de versions de mémoire. Ajustez les paramètres de configuration: utilisez la stratégie pour éliminer les paires de valeurs clés les moins récemment utilisées. Utilisez le mécanisme de persistance: sauvegardez régulièrement les données et redémarrez Redis pour nettoyer les fragments. Surveillez l'utilisation de la mémoire: découvrez les problèmes en temps opportun et prenez des mesures.
