
 Périphériques technologiques
IA
Tutoriel postgresml: faire l'apprentissage automatique avec SQL
Périphériques technologiques
IA
Tutoriel postgresml: faire l'apprentissage automatique avec SQL
Tutoriel postgresml: faire l'apprentissage automatique avec SQL
Mar 07, 2025 am 09:16 AM
La tendance dominante de l'apprentissage automatique consiste à transférer des données dans l'environnement du modèle pour la formation. Cependant, que se passe-t-il si nous inversions ce processus? étant donné que les bases de données modernes sont nettement plus grandes que les modèles d'apprentissage automatique, ne serait-il pas plus efficace de déplacer les modèles vers les ensembles de données?
Il s'agit du concept fondamental derrière PostgreSML - les données restent à son emplacement et vous apportez votre code à la base de données. Cette approche inversée de l'apprentissage automatique offre de nombreux avantages pratiques qui remettent en question les notions conventionnelles d'une ?base de données?.
postgresml: un aper?u et ses avantages
PostgreSML est une plate-forme d'apprentissage automatique complète construite sur la base de données PostgreSQL largement utilisée. Il introduit une nouvelle approche appelée apprentissage automatique "en database", vous permettant d'exécuter diverses taches ML dans SQL sans avoir besoin d'outils distincts pour chaque étape.
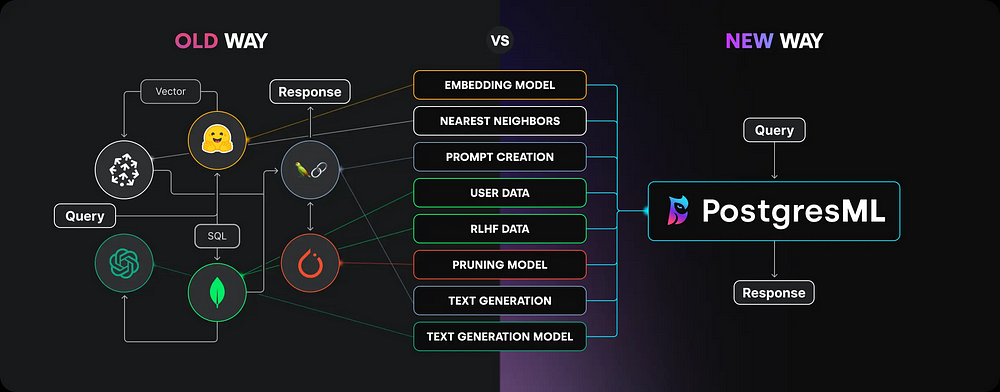
Malgré sa nouveauté relative, PostgreSML offre plusieurs avantages clés:
- In-Database ML: Traintes, déploie et exécute des modèles ML directement dans votre base de données PostgreSQL. Cela élimine le besoin de transfert de données constant entre la base de données et les cadres ML externes, améliorant l'efficacité et réduisant la latence.
- API SQL: exploite SQL pour les modèles de formation, de réglage fin et de déploiement d'apprentissage automatique. Cela simplifie les workflows pour les analystes de données et les scientifiques moins familiers avec plusieurs frameworks ML.
- Modèles pré-formés: intègre de manière transparente à HuggingFace, donnant accès à de nombreux modèles pré-formés comme Llama, Falcon, Bert et Mistral.
- Personnalisation et flexibilité: prend en charge une large gamme d'algorithmes de Scikit-Learn, XgBoost, LGBM, Pytorch et Tensorflow, permettant de diverses taches d'apprentissage supervisées directement dans la base de données.
- Intégration de l'écosystème: Fonctionne avec n'importe quel environnement prenant en charge les Postgres et propose des SDK pour plusieurs langages de programmation (JavaScript, Python et Rust sont particulièrement bien soutenus).

Ce tutoriel démontrera ces fonctionnalités à l'aide d'un flux de travail d'apprentissage automatique typique:
- Chargement des données
- Prétraitement des données
- Formation du modèle
- Hyperparamètre Fineding
- Déploiement de la production
Toutes ces étapes seront effectuées dans une base de données Postgres. Commen?ons!
Un flux de travail d'apprentissage supervisé complet avec postgresml
Début: PostgreSML Free Tier
- Créez un compte gratuit à http://ipnx.cn/link/3349958a3e56580d4e415da345703886 :
- Sélectionnez le niveau gratuit, qui propose des ressources généreuses:
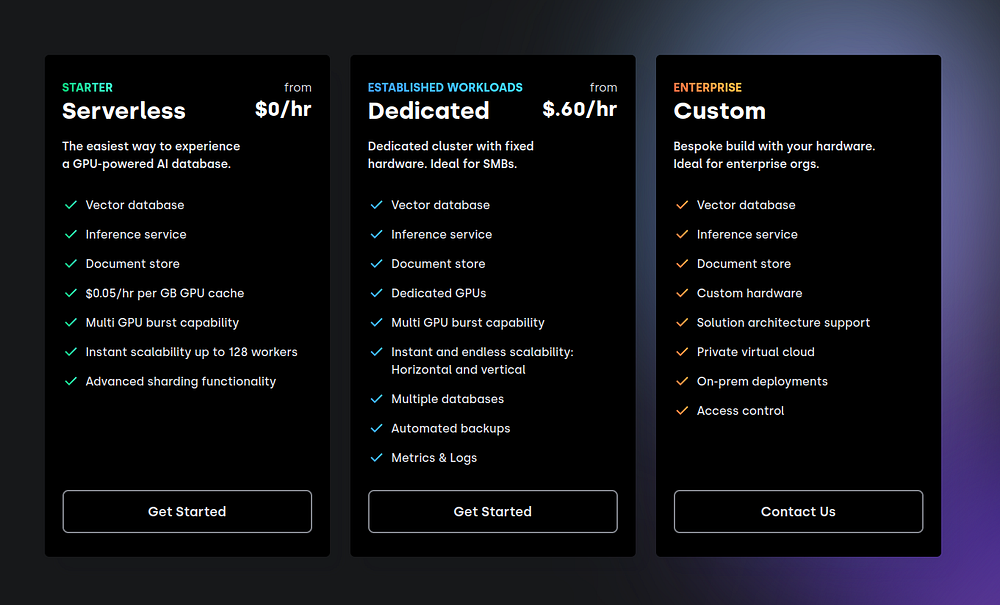
Après l'inscription, vous accéderez à votre console postgresml pour gérer les projets et les ressources.

La section "Gérer" vous permet d'étendre votre environnement en fonction des besoins de calcul.

1. Installation et configuration de Postgres
PostgreSML nécessite PostgreSQL. Des guides d'installation pour diverses plates-formes sont disponibles:
- Windows
- mac os
- Linux
Pour WSL2, les commandes suivantes suffisent:
sudo apt update sudo apt install postgresql postgresql-contrib sudo passwd postgres # Set a new Postgres password # Close and reopen your terminal
Vérifiez l'installation:
psql --version
Pour une expérience plus conviviale que le terminal, considérez l'extension VScode.

2. Connexion de la base de données
Utilisez les détails de la connexion à partir de votre console postgresml:
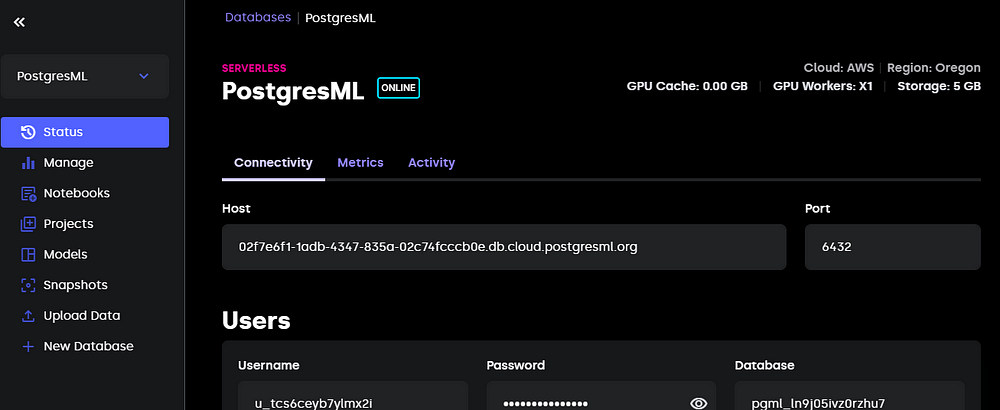
Connectez-vous en utilisant psql:
psql -h "host" -U "username" -p 6432 -d "database_name"
Alternativement, utilisez l'extension VScode comme décrit dans sa documentation.
Activer l'extension PGML:
CREATE EXTENSION IF NOT EXISTS pgml;
Vérifiez l'installation:
SELECT pgml.version();
3. Chargement des données
Nous utiliserons l'ensemble de données Diamonds de Kaggle. Téléchargez-le en CSV ou utilisez cet extrait Python:
import seaborn as sns
diamonds = sns.load_dataset("diamonds")
diamonds.to_csv("diamonds.csv", index=False)
Créez le tableau:
CREATE TABLE IF NOT EXISTS diamonds ( index SERIAL PRIMARY KEY, carat FLOAT, cut VARCHAR(255), color VARCHAR(255), clarity VARCHAR(255), depth FLOAT, table_ FLOAT, price INT, x FLOAT, y FLOAT, z FLOAT );
remplir la table:
INSERT INTO diamonds (carat, cut, color, clarity, depth, table_, price, x, y, z) FROM '~/full/path/to/diamonds.csv' DELIMITER ',' CSV HEADER;
Vérifiez les données:
SELECT * FROM diamonds LIMIT 10;
4. Formation du modèle
Formation de base
former un régresseur XGBOost:
SELECT pgml.train( project_name => 'Diamond prices prediction', task => 'regression', relation_name => 'diamonds', y_column_name => 'price', algorithm => 'xgboost' );
former un classificateur multi-classes:
SELECT pgml.train( project_name => 'Diamond cut quality prediction', task => 'classification', relation_name => 'diamonds', y_column_name => 'cut', algorithm => 'xgboost', test_size => 0.1 );
Prétraitement
entra?ner un modèle forestier aléatoire avec le prétraitement:
SELECT pgml.train(
project_name => 'Diamond prices prediction',
task => 'regression',
relation_name => 'diamonds',
y_column_name => 'price',
algorithm => 'random_forest',
preprocess => '{
"carat": {"scale": "standard"},
"depth": {"scale": "standard"},
"table_": {"scale": "standard"},
"cut": {"encode": "target", "scale": "standard"},
"color": {"encode": "target", "scale": "standard"},
"clarity": {"encode": "target", "scale": "standard"}
}'::JSONB
);
postgresml fournit diverses options de prétraitement (codage, imputé, échelle).
Spécification des hyperparamètres
Former un régresseur XGBOost avec des hyperparamètres personnalisés:
sudo apt update sudo apt install postgresql postgresql-contrib sudo passwd postgres # Set a new Postgres password # Close and reopen your terminal
Tuning hyperparamètre
Effectuer une recherche sur la grille:
psql --version
5. évaluation du modèle
Utiliser pgml.predict pour les prédictions:
psql -h "host" -U "username" -p 6432 -d "database_name"
Pour utiliser un modèle spécifique, spécifiez son identifiant:
CREATE EXTENSION IF NOT EXISTS pgml;
Récupérer les ID du modèle:
SELECT pgml.version();
6. Déploiement du modèle
PostgreSML déploie automatiquement le modèle le mieux performant. Pour un contr?le plus fin, utilisez pgml.deploy:
import seaborn as sns
diamonds = sns.load_dataset("diamonds")
diamonds.to_csv("diamonds.csv", index=False)
Les stratégies de déploiement incluent best_score, most_recent et rollback.
Exploration plus approfondie du postgresml
postgresml s'étend au-delà de l'apprentissage supervisé. La page d'accueil présente un éditeur SQL pour l'expérimentation. La construction d'un service ML orienté consommateur pourrait impliquer:
- Création d'une interface utilisateur (par exemple, en utilisant Streamlit ou Taipy).
- Développer un backend (python, node.js).
- Utilisation de bibliothèques comme
psycopg2oupg-promisepour l'interaction de la base de données. - Données de prétraitement dans le backend.
- déclencher
pgml.predictlors de l'interaction utilisateur.
Conclusion
PostgreSML offre une nouvelle approche de l'apprentissage automatique. Pour approfondir votre compréhension, explorez la documentation PostgreSML et envisagez des ressources comme les cours SQL de DataCamp et les tutoriels fondamentaux de l'IA.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
échangez les visages dans n'importe quelle vidéo sans effort grace à notre outil d'échange de visage AI entièrement gratuit?!

Article chaud
Outils chauds

Bloc-notes++7.3.1
éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Kimi K2: le modèle agentique open source le plus puissant
Jul 12, 2025 am 09:16 AM
Kimi K2: le modèle agentique open source le plus puissant
Jul 12, 2025 am 09:16 AM
Rappelez-vous le flot de modèles chinois open source qui a perturbé l'industrie du Genai plus t?t cette année? Alors que Deepseek a fait la majeure partie des titres, Kimi K1.5 était l'un des noms importants de la liste. Et le modèle était assez cool.
 Grok 4 vs Claude 4: Quel est le meilleur?
Jul 12, 2025 am 09:37 AM
Grok 4 vs Claude 4: Quel est le meilleur?
Jul 12, 2025 am 09:37 AM
à la mi-2025, l'AI ?Arme Race? se réchauffe, et Xai et Anthropic ont tous deux publié leurs modèles phares, Grok 4 et Claude 4.
 10 robots humano?des incroyables qui marchent déjà parmi nous aujourd'hui
Jul 16, 2025 am 11:12 AM
10 robots humano?des incroyables qui marchent déjà parmi nous aujourd'hui
Jul 16, 2025 am 11:12 AM
Mais nous n'aurons probablement pas à attendre même 10 ans pour en voir un. En fait, ce qui pourrait être considéré comme la première vague de machines vraiment utiles, de type humain, est déjà là. Les dernières années ont vu un certain nombre de prototypes et de modèles de production sortant de T
 L'ingénierie contextuelle est la & # 039; New & # 039; Ingénierie rapide
Jul 12, 2025 am 09:33 AM
L'ingénierie contextuelle est la & # 039; New & # 039; Ingénierie rapide
Jul 12, 2025 am 09:33 AM
Jusqu'à l'année précédente, l'ingénierie rapide était considérée comme une compétence cruciale pour interagir avec les modèles de langage grand (LLM). Récemment, cependant, les LLM ont considérablement progressé dans leurs capacités de raisonnement et de compréhension. Naturellement, nos attentes
 6 taches manus ai peut faire en quelques minutes
Jul 06, 2025 am 09:29 AM
6 taches manus ai peut faire en quelques minutes
Jul 06, 2025 am 09:29 AM
Je suis s?r que vous devez conna?tre l'agent général de l'IA, Manus. Il a été lancé il y a quelques mois, et au cours des mois, ils ont ajouté plusieurs nouvelles fonctionnalités à leur système. Maintenant, vous pouvez générer des vidéos, créer des sites Web et faire beaucoup de MO
 L'application mobile d'immersité de Leia apporte une profondeur 3D aux photos de tous les jours
Jul 09, 2025 am 11:17 AM
L'application mobile d'immersité de Leia apporte une profondeur 3D aux photos de tous les jours
Jul 09, 2025 am 11:17 AM
Construit sur le moteur de profondeur neuronale propriétaire de Leia, l'application traite des images fixes et ajoute de la profondeur naturelle avec un mouvement simulé - comme les casseroles, les zooms et les effets de parallaxe - pour créer de courts bobines vidéo qui donnent l'impression de pénétrer dans le SCE
 Ces modèles d'IA n'ont pas appris la langue, ils ont appris la stratégie
Jul 09, 2025 am 11:16 AM
Ces modèles d'IA n'ont pas appris la langue, ils ont appris la stratégie
Jul 09, 2025 am 11:16 AM
Une nouvelle étude de chercheurs du King’s College de Londres et de l’Université d’Oxford partage les résultats de ce qui s'est passé lorsque Openai, Google et Anthropic ont été jetés ensemble dans un concours fardé basé sur le dilemme du prisonnier itéré. Ce n'était pas
 Quels sont les 7 types d'agents d'IA?
Jul 11, 2025 am 11:08 AM
Quels sont les 7 types d'agents d'IA?
Jul 11, 2025 am 11:08 AM
Imaginez quelque chose de sophistiqué, comme un moteur d'IA prêt à donner des commentaires détaillés sur une nouvelle collection de vêtements de Milan, ou une analyse de marché automatique pour une entreprise opérant dans le monde entier, ou des systèmes intelligents gérant une grande flotte de véhicules.
