
 Périphériques technologiques
IA
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Périphériques technologiques
IA
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM

éditeur | KX
Dans le domaine de la recherche et du développement de médicaments, prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands est crucial pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le r?le important des informations sur la surface moléculaire dans les interactions protéine-ligand.
Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour différents modes. Alignement des fonctionnalités entre les états.
Les résultats expérimentaux montrent que cette méthode atteint des performances de pointe dans la prédiction de l'affinité de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre.
Une recherche connexe intitulée ? Prédiction de l'affinité de liaison protéine-ligand multimodale basée sur la surface ? a été publiée sur ? Bioinformatics ? le 21 juin.

Recherche sur la prédiction de l'affinité de liaison protéine-ligand
En tant qu'étape clé de la découverte de médicaments, la prédiction de l'affinité de liaison protéine-ligand a été étudiée de manière approfondie depuis longtemps, ce qui est crucial pour un dépistage efficace et précis des médicaments.
Les outils traditionnels de découverte de médicaments assistés par ordinateur utilisent des fonctions de notation (SF) pour estimer approximativement l'affinité de liaison protéine-ligand, mais avec une faible précision. Les méthodes de simulation de dynamique moléculaire peuvent fournir des estimations d’affinité de liaison plus précises, mais sont souvent co?teuses et longues.
Avec le développement de la technologie informatique et l’abondance croissante de données biologiques à grande échelle, les méthodes basées sur l’apprentissage profond ont montré un grand potentiel dans le domaine de la prédiction de l’affinité de liaison protéine-ligand.
Cependant, les recherches actuelles utilisent principalement des représentations basées sur des séquences ou des structures pour prédire l'affinité de liaison protéine-ligand, et il existe relativement peu d'études sur les informations de surface des protéines qui sont cruciales pour les interactions protéine-ligand.
Une surface moléculaire est une représentation de haut niveau de la structure d'une protéine, qui présente des motifs chimiques et géométriques qui servent d'empreintes digitales des modèles d'interaction de la protéine avec d'autres biomolécules. Par conséquent, certaines études ont commencé à utiliser les informations sur la surface des protéines pour prédire l’affinité de liaison protéine-ligand.
Mais les méthodes existantes se concentrent principalement sur les données monomodales et ignorent les informations multimodales des protéines. De plus, lors du traitement de l'information multimodale des protéines, les méthodes traditionnelles connectent généralement les caractéristiques de différentes modalités de manière directe sans tenir compte de l'hétérogénéité entre elles, ce qui entra?ne l'incapacité d'exploiter efficacement la complémentarité entre les modalités.
Nouveau cadre d'extraction de caractéristiques multimodales
Ici, les chercheurs proposent un nouveau cadre d'extraction de caractéristiques multimodales (MFE) qui combine pour la première fois des informations provenant de la surface des protéines, de la structure 3D et de la séquence.
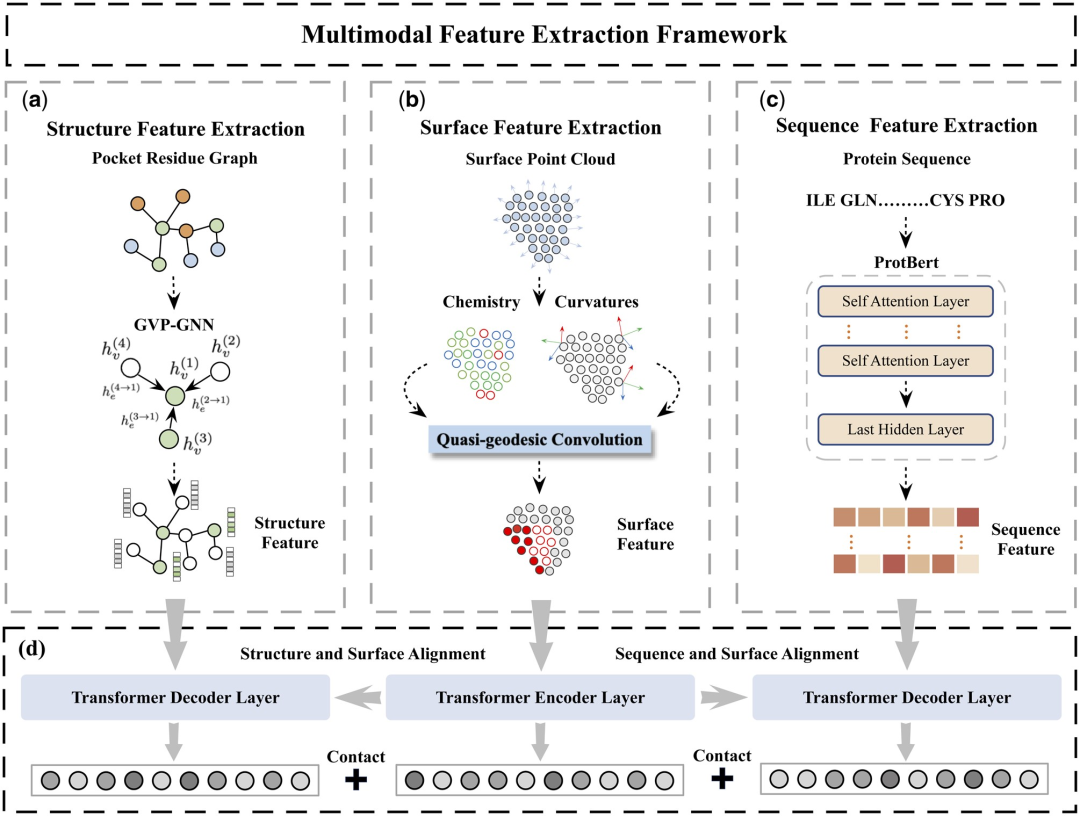
Plus précisément, l'étude a con?u deux composants principaux : le module d'extraction de caractéristiques protéiques et le module de comparaison de caractéristiques multimodales.
Le module d'extraction de caractéristiques des protéines est utilisé pour extraire les incorporations initiales à partir des informations sur la surface, la structure et la séquence des protéines.
Dans le module de comparaison de fonctionnalités multimodales, le mécanisme d'attention croisée est utilisé pour réaliser une comparaison de fonctionnalités entre la structure protéique, l'intégration de séquences et l'intégration de surface afin d'obtenir une intégration de fonctionnalités unifiée et riche en informations.
Comparé aux méthodes de pointe actuelles, le cadre proposé permet d'obtenir les meilleurs résultats dans la tache de prédiction de l'affinité de liaison protéine-ligand.
Performance SOTA
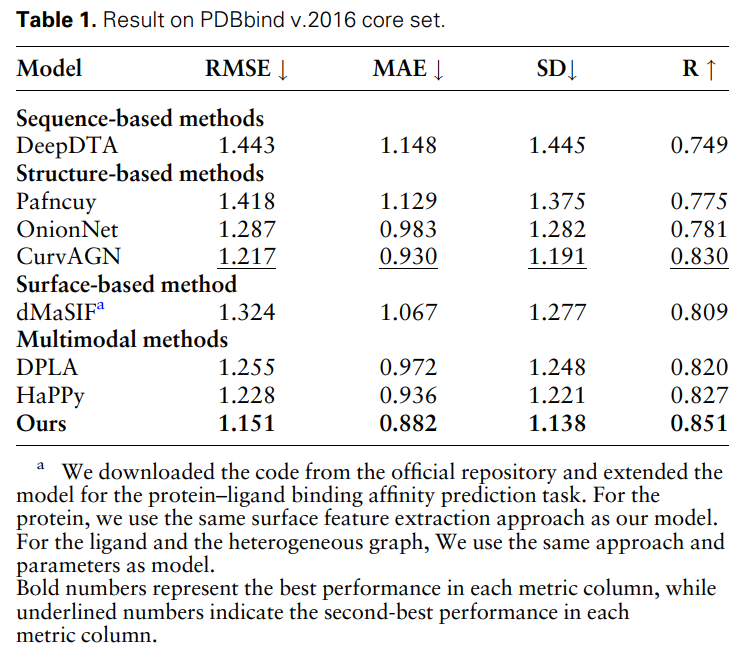
Le Tableau 1 montre les résultats du MFE et d'autres modèles de base sur la tache de prédiction de l'affinité de liaison protéine-ligand. Tous les modèles ont utilisé la même méthode de partitionnement des ensembles de formation et de validation et ont été testés sur l'ensemble de base PDBbind (version 2016). On peut constater que la méthode MFE atteint des performances SOTA par rapport à toutes les références.
étude d'ablation
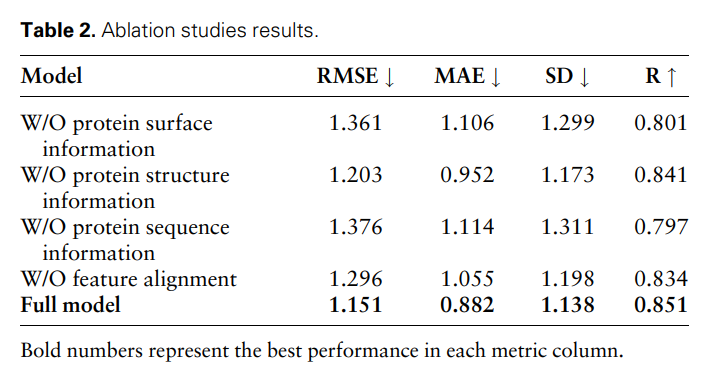
Pour prouver davantage l'efficacité et la nécessité de différentes caractéristiques modales et comparaisons de caractéristiques, les chercheurs ont mené les études d'ablation suivantes?: sans informations sur la surface des protéines, sans informations sur la structure des protéines, sans o informations sur les séquences protéiques et alignements sans particularités. Les résultats sont présentés dans le tableau 2 et la figure 2.
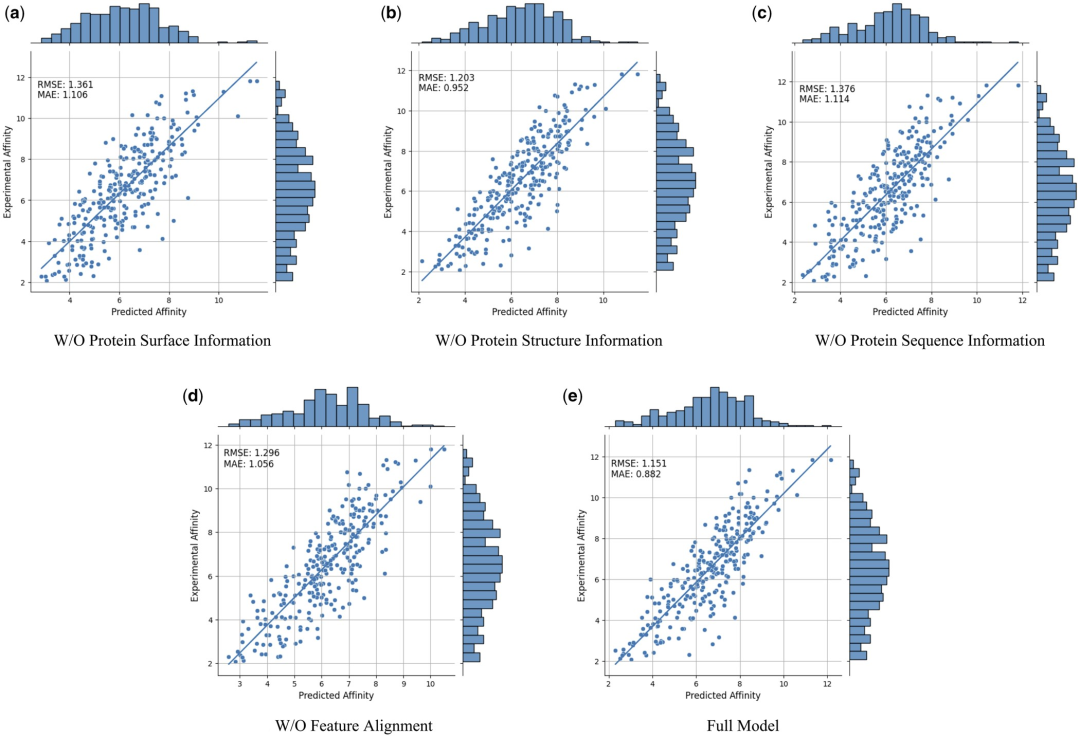
Figure 2?: Résultats de l’étude d’ablation. (Source : article)
Les résultats montrent que lorsque les informations de surface sont supprimées, les performances chutent considérablement, indiquant que les informations de surface jouent un r?le crucial dans le modèle. De même, l'exclusion des informations structurelles ou de séquence entra?ne une dégradation des performances, tandis que l'élimination des informations de séquence entra?ne une dégradation plus prononcée. En effet, les informations de séquence contiennent des informations globales sur la protéine, ce qui est crucial pour que le modèle comprenne pleinement la protéine.
De plus, sans comparaison des fonctionnalités, les performances du modèle diminueront. Cela souligne l'importance de la comparaison des caractéristiques dans le traitement des données multimodales, car elle contribue à réduire l'hétérogénéité entre les différentes caractéristiques modales, améliorant ainsi la capacité du modèle à intégrer efficacement différentes caractéristiques modales.
Analyse des hyperparamètres
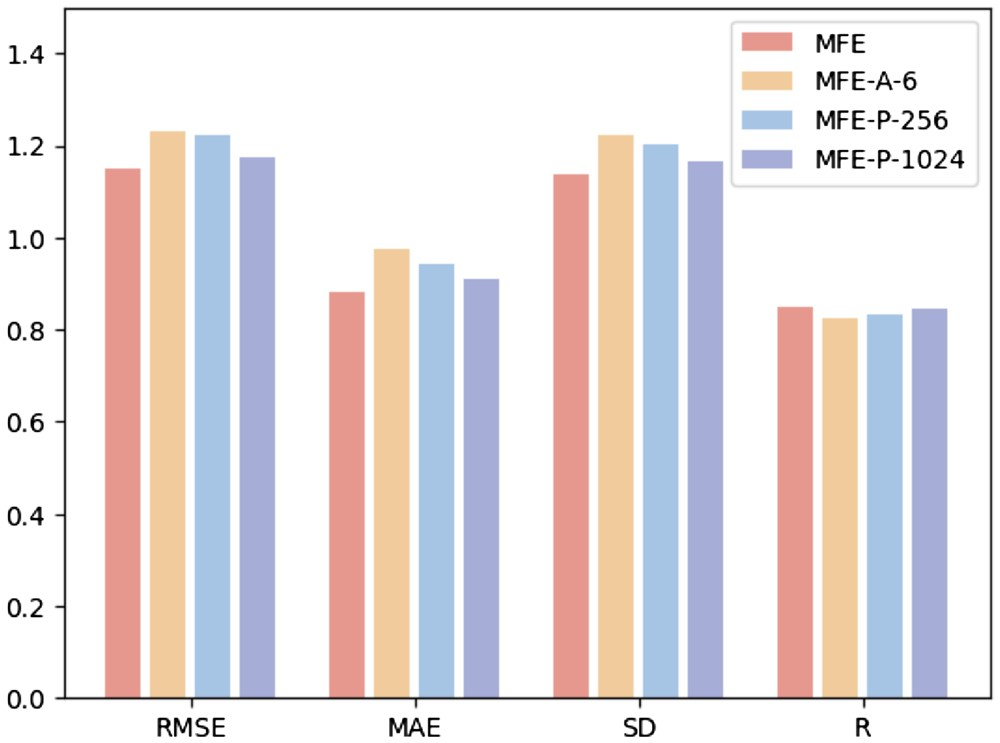
Afin d'étudier l'impact de différents hyperparamètres sur les performances du modèle, les chercheurs ont mené les trois expériences suivantes?: (i) MFE-A-6?: n'utilisez que 6 types d'atomes de base pour représenter les produits chimiques. propriétés de la surface, notamment l'hydrogène, le carbone, l'azote, l'oxygène, le phosphore et le soufre?; (ii) MFE-P-256?: seuls les 256 points de surface les plus proches du centre du ligand sont sélectionnés comme surface de la poche protéique?; -P -1024?: Sélectionnez les 1024 points de surface les plus proches du centre du ligand comme surface de la poche protéique.
La figure 3 montre les résultats de trois méthodes différentes de sélection d'hyperparamètres sur la tache de prédiction d'affinité de liaison protéine-ligand.
Analyse et visualisation de l'alignement des caractéristiques
Afin d'étudier en profondeur l'impact de l'alignement des caractéristiques sur les performances du modèle, les chercheurs ont utilisé l'analyse en composantes principales (ACP) pour effectuer une réduction de dimensionnalité et une sommation de la surface des protéines, de la structure et séquencer les fonctionnalités dans l'ensemble de test Analyse visuelle. Cette approche vise à déterminer si l'alignement des fonctionnalités peut atténuer l'hétérogénéité entre les intégrations multimodales.
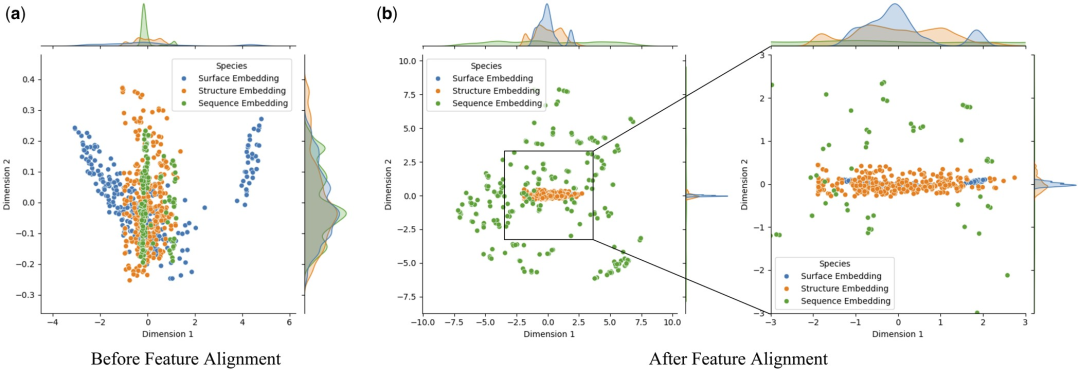
La recherche a révélé que l'alignement des caractéristiques améliorait considérablement la cohérence entre la surface, la structure et l'intégration des séquences des protéines. Cela est d? à l'optimisation des interactions de fonctionnalités multimodales dans Transformer via le mécanisme d'attention, qui calcule les pondérations d'attention entre différentes fonctionnalités. Cela améliore la capacité du modèle à capturer des informations clés, permettant aux données de différentes modalités d'être plus étroitement regroupées dans l'espace des fonctionnalités, réduisant ainsi le bruit et les erreurs dans l'identification par le modèle des interactions protéine-ligand.
Enfin, les chercheurs ont conclu : ? En résumé, en étudiant la surface des protéines, nous pouvons mieux comprendre comment les protéines interagissent avec d’autres biomolécules. Dans des travaux futurs, nous explorerons plus en profondeur les surfaces des protéines pour révéler leur application plus large. bioinformatique"
Remarque : la couverture provient d'Internet
.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
échangez les visages dans n'importe quelle vidéo sans effort grace à notre outil d'échange de visage AI entièrement gratuit?!

Article chaud
Outils chauds

Bloc-notes++7.3.1
éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Bytedance Cutting lance le super abonnement SVIP?: 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP?: 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Repoussant les limites de la détection de défauts traditionnelle, ??Defect Spectrum?? permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Repoussant les limites de la détection de défauts traditionnelle, ??Defect Spectrum?? permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Dans la fabrication moderne, une détection précise des défauts est non seulement la clé pour garantir la qualité des produits, mais également la clé de l’amélioration de l’efficacité de la production. Cependant, les ensembles de données de détection de défauts existants manquent souvent de précision et de richesse sémantique requises pour les applications pratiques, ce qui rend les modèles incapables d'identifier des catégories ou des emplacements de défauts spécifiques. Afin de résoudre ce problème, une équipe de recherche de premier plan composée de l'Université des sciences et technologies de Hong Kong, Guangzhou et de Simou Technology a développé de manière innovante l'ensemble de données ? DefectSpectrum ?, qui fournit une annotation à grande échelle détaillée et sémantiquement riche des défauts industriels. Comme le montre le tableau 1, par rapport à d'autres ensembles de données industrielles, l'ensemble de données ? DefectSpectrum ? fournit le plus grand nombre d'annotations de défauts (5 438 échantillons de défauts) et la classification de défauts la plus détaillée (125 catégories de défauts).
 Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
La communauté ouverte LLM est une époque où une centaine de fleurs fleurissent et s'affrontent. Vous pouvez voir Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 et bien d'autres. excellents interprètes. Cependant, par rapport aux grands modèles propriétaires représentés par le GPT-4-Turbo, les modèles ouverts présentent encore des lacunes importantes dans de nombreux domaines. En plus des modèles généraux, certains modèles ouverts spécialisés dans des domaines clés ont été développés, tels que DeepSeek-Coder-V2 pour la programmation et les mathématiques, et InternVL pour les taches de langage visuel.
 Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Editeur | KX à ce jour, les détails structurels et la précision déterminés par cristallographie, des métaux simples aux grandes protéines membranaires, sont inégalés par aucune autre méthode. Cependant, le plus grand défi, appelé problème de phase, reste la récupération des informations de phase à partir d'amplitudes déterminées expérimentalement. Des chercheurs de l'Université de Copenhague au Danemark ont ??développé une méthode d'apprentissage en profondeur appelée PhAI pour résoudre les problèmes de phase cristalline. Un réseau neuronal d'apprentissage en profondeur formé à l'aide de millions de structures cristallines artificielles et de leurs données de diffraction synthétique correspondantes peut générer des cartes précises de densité électronique. L'étude montre que cette méthode de solution structurelle ab initio basée sur l'apprentissage profond peut résoudre le problème de phase avec une résolution de seulement 2 Angstr?ms, ce qui équivaut à seulement 10 à 20 % des données disponibles à la résolution atomique, alors que le calcul ab initio traditionnel
 Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Pour l’IA, l’Olympiade mathématique n’est plus un problème. Jeudi, l'intelligence artificielle de Google DeepMind a réalisé un exploit : utiliser l'IA pour résoudre la vraie question de l'Olympiade mathématique internationale de cette année, l'OMI, et elle n'était qu'à un pas de remporter la médaille d'or. Le concours de l'OMI qui vient de se terminer la semaine dernière comportait six questions portant sur l'algèbre, la combinatoire, la géométrie et la théorie des nombres. Le système d'IA hybride proposé par Google a répondu correctement à quatre questions et a marqué 28 points, atteignant le niveau de la médaille d'argent. Plus t?t ce mois-ci, le professeur titulaire de l'UCLA, Terence Tao, venait de promouvoir l'Olympiade mathématique de l'IA (AIMO Progress Award) avec un prix d'un million de dollars. De manière inattendue, le niveau de résolution de problèmes d'IA s'était amélioré à ce niveau avant juillet. Posez les questions simultanément sur l'OMI. La chose la plus difficile à faire correctement est l'OMI, qui a la plus longue histoire, la plus grande échelle et la plus négative.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un r?le essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 ao?t?: HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 ao?t?: HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er ao?t, SK Hynix a publié un article de blog aujourd'hui (1er ao?t), annon?ant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, états-Unis, du 6 au 8 ao?t, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
 PRO | Pourquoi les grands modèles basés sur le MoE méritent-ils davantage d'attention??
Aug 07, 2024 pm 07:08 PM
PRO | Pourquoi les grands modèles basés sur le MoE méritent-ils davantage d'attention??
Aug 07, 2024 pm 07:08 PM
En 2023, presque tous les domaines de l’IA évoluent à une vitesse sans précédent. Dans le même temps, l’IA repousse constamment les limites technologiques de domaines clés tels que l’intelligence embarquée et la conduite autonome. Sous la tendance multimodale, le statut de Transformer en tant qu'architecture dominante des grands modèles d'IA sera-t-il ébranlé ? Pourquoi l'exploration de grands modèles basés sur l'architecture MoE (Mixture of Experts) est-elle devenue une nouvelle tendance dans l'industrie?? Les modèles de grande vision (LVM) peuvent-ils constituer une nouvelle avancée dans la vision générale?? ...Dans la newsletter des membres PRO 2023 de ce site publiée au cours des six derniers mois, nous avons sélectionné 10 interprétations spéciales qui fournissent une analyse approfondie des tendances technologiques et des changements industriels dans les domaines ci-dessus pour vous aider à atteindre vos objectifs dans le nouveau année. Cette interprétation provient de la Week50 2023
