
 Technology peripherals
AI
No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Technology peripherals
AI
No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
At the forefront of software technology, UIUC Zhang Lingming's group, together with researchers from the BigCode organization, recently announced the StarCoder2-15B-Instruct large code model.
This innovative achievement has made a significant breakthrough in the code generation task, successfully surpassing CodeLlama-70B-Instruct and reaching the top of the code generation performance list.

The uniqueness of StarCoder2-15B-Instruct lies in its pure self-alignment strategy. The entire training process is open, transparent, and completely autonomous and controllable.
The model generates thousands of instructions through StarCoder2-15B, in response to fine-tuning the StarCoder-15B base model, without relying on expensive manual annotation data, or from commercial applications such as GPT4 Obtain data from large models to avoid potential copyright issues.
In the HumanEval test, StarCoder2-15B-Instruct stood out with a Pass@1 score of 72.6%, which was improved from 72.0% of CodeLlama-70B-Instruct.
In the evaluation on the LiveCodeBench dataset, this self-aligned model even outperformed similar models trained on GPT-4 generated data. This result demonstrates that a large model can also effectively learn how to align similarly to humans using data within its own distribution, without relying on the biased distribution of the large model from an external teacher.
The successful implementation of this project has received strong support from Arjun Guha’s research group at Northeastern University, University of California, Berkeley, ServiceNow and Hugging Face and other institutions.
Technical Reveal
The data generation process of StarCoder2-Instruct mainly includes three core steps:
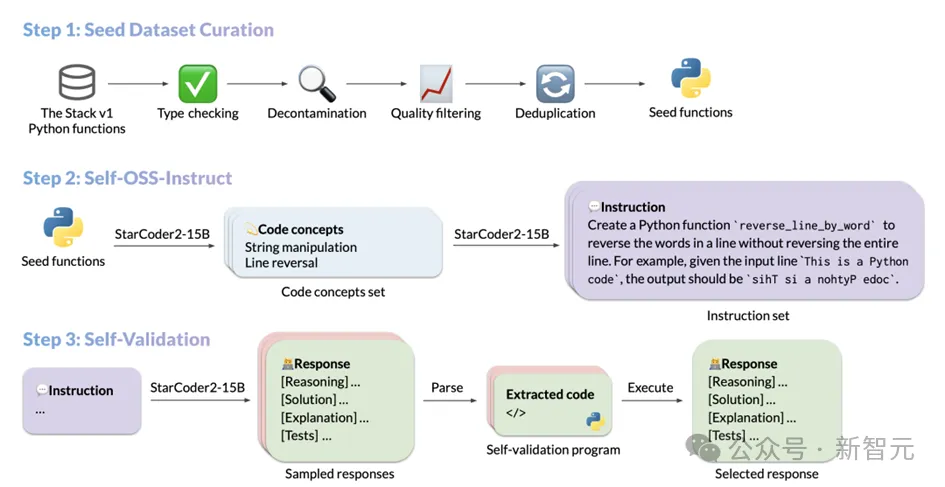
1. Collection of seed code snippets: The team selected high-quality, diverse seed functions from The Stack v1 , these functions are drawn from a massive corpus of licensed source code. Through strict filtering and screening, the quality and diversity of seed codes are ensured;
2. Generation of diverse instructions:Based on Different programming concepts in the seed function, StarCoder2-15B-Instruct can create diverse and realistic code instructions. These instructions cover a variety of programming scenarios from data deserialization to list concatenation, recursion, etc.;
3. Generation of high-quality responses:For each instruction, the model adopts a compilation and run-guided self-verification method to ensure that the generated response is accurate and of high quality.
The specific operations of each step are as follows:
The process of selecting seed code snippets
In order to improve the code model's ability to follow instructions, the model needs extensive exposure to and learning of different programming principles and practical operations. StarCoder2-15B-Instruct is inspired by OSS-Instruct and draws inspiration from open source code snippets, especially the well-formatted and clearly structured Python seed functions in The Stack V1.
When building its basic data set, StarCoder2-15B-Instruct conducted in-depth exploration of The Stack V1, selected all Python functions with documented instructions, and automatically analyzed them with the help of the autoimport function and inferred the dependencies required by these functions.
In order to ensure the purity and high quality of the data set, StarCoder2-15B-Instruct has carefully filtered and filtered all selected functions.
First of all, strict type checking is performed through the Pyright type checker to exclude all functions that may produce static errors, thus ensuring the accuracy and reliability of the data.
Next, through precise string matching technology, codes and prompts that are potentially related to the evaluation data set are identified and eliminated to avoid data contamination. In terms of document quality, StarCoder2-15B-Instruct adopts a unique screening mechanism.
It uses its own evaluation capabilities to show 7 sample prompts to the model, allowing the model to judge whether the document quality of each function meets the standard, thereby deciding whether to include it in the final data set.
This method based on model self-judgment not only improves the efficiency and accuracy of data screening, but also ensures the high quality and consistency of the data set.
Finally, in order to avoid data redundancy and duplication, StarCoder2-15B-Instruct uses MinHash and locality-sensitive hashing algorithms to deduplicate functions in the data set. By setting a Jaccard similarity threshold of 0.5, duplicate functions with high similarity are effectively removed, ensuring the uniqueness and diversity of the data set.
After this series of fine screening and filtering, StarCoder2-15B-Instruct finally selected 250,000 high-quality Python functions from 5 million Python functions with documentation. function as its seed data set. This approach is heavily inspired by the MultiPL-T data collection process.
Generation of diverse instructions
##When StarCoder2-15B-Instruct completes the seed After collecting functions, it uses Self-OSS-Instruct technology to create diverse programming instructions. The core of this technology is to enable the StarCoder2-15B base model to autonomously generate corresponding instructions for a given seed code fragment through contextual learning.
To achieve this goal, StarCoder2-15B-Instruct has carefully designed 16 examples, each of which follows the structure of (code snippets, concepts, instructions). The instruction generation process is subdivided into two stages:
Code concept identification: In this stage, StarCoder2-15B will conduct an in-depth analysis of each seed function and generate a code containing A list of key code concepts in this function. These concepts broadly cover the basic principles and techniques in the field of programming, such as pattern matching, data type conversion, etc., which are of extremely high practical value to developers.
Instruction creation: Based on the recognized code concept, StarCoder2-15B will further generate corresponding coding task instructions. This process is designed to ensure that the generated instructions accurately reflect the core functionality and requirements of the code fragment.
Through the above process, StarCoder2-15B-Instruct finally successfully generated up to 238k instructions, greatly enriching its training data set and providing improved performance in programming tasks. Strong support.
Response self-verification mechanism
After obtaining the Self-OSS-Instruct generated After the instruction, the key task of StarCoder2-15B-Instruct is to match a high-quality response to each instruction.
Traditionally, people tend to rely on more powerful teacher models such as GPT-4 to obtain these responses, but not only may this approach face copyright licensing difficulties, but external models are not Always within reach or accurate. More importantly, relying on external models may introduce distribution differences between teachers and students, which may affect the accuracy of the final results.
To overcome these challenges, StarCoder2-15B-Instruct introduces a self-verification mechanism. The core idea of ??this mechanism is to allow the StarCoder2-15B model to create corresponding test cases on its own after generating a natural language response. This process is similar to the self-testing process a developer goes through after writing code.
Specifically, for each instruction, StarCoder2-15B will generate 10 samples containing natural language responses and corresponding test cases. StarCoder2-15B-Instruct then executes these test cases in a sandbox environment to verify the validity of the responses. Any samples that fail in executing the test will be filtered out.
After this strict screening process, StarCoder2-15B-Instruct will randomly select one from the tested responses of each instruction and add it to the final SFT data set. Throughout the process, StarCoder2-15B-Instruct generated a total of 2.4 million response samples (10 samples per instruction) for 238k instructions. After adopting a sampling strategy of 0.7, 500,000 samples successfully passed the execution test.
In order to ensure the diversity and quality of the data set, StarCoder2-15B-Instruct also performs deduplication processing. In the end, 50,000 commands were left, each with a randomly selected, tested and verified high-quality response. These responses constitute the final SFT data set of StarCoder2-15B-Instruct, providing a solid foundation for subsequent training and application of the model.
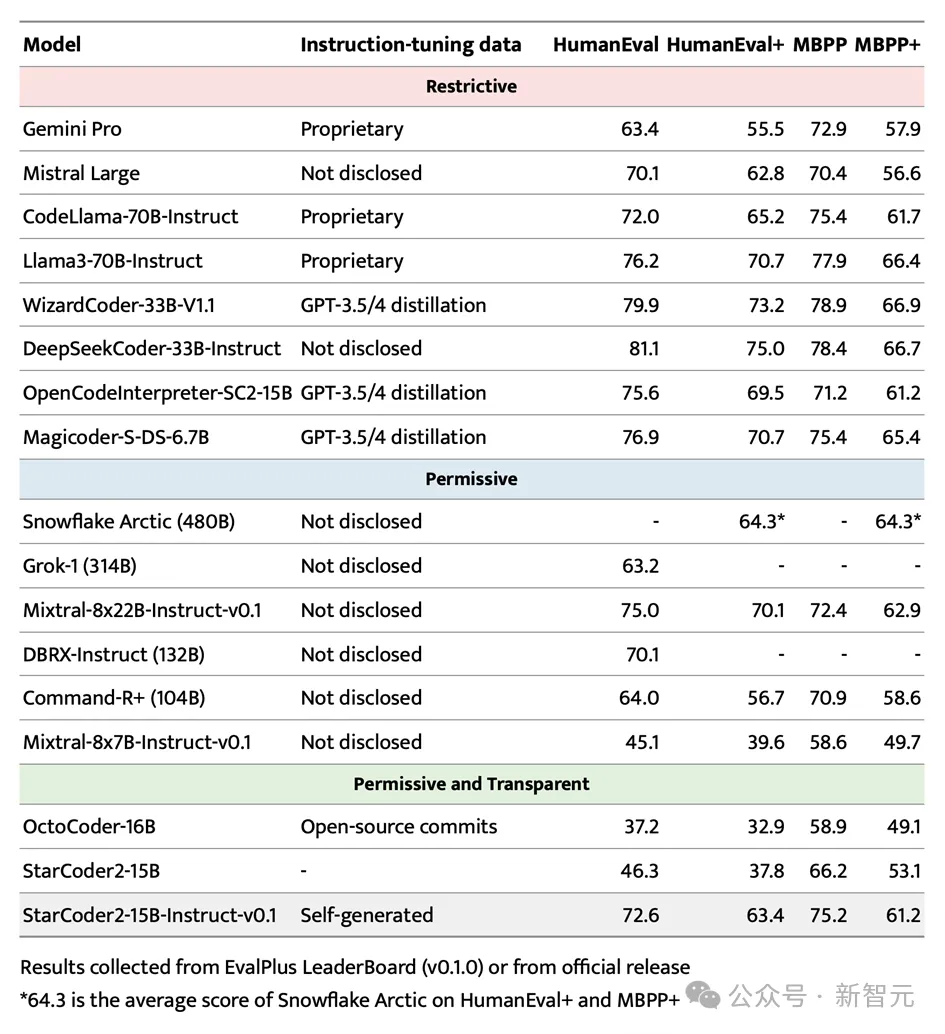
Superior performance and comprehensive evaluation of StarCoder2-15B-InstructIn the high-profile EvalPlus benchmark, StarCoder2- With its advantages of scale, 15B-Instruct successfully stood out and became the most outstanding autonomous and controllable large-scale model.
Not only does it surpass the larger Grok-1 Command-R+ and DBRX, it also matches industry leaders such as Snowflake Arctic 480B and Mixtral-8x22B-Instruct.
It is worth mentioning that StarCoder2-15B-Instruct is the first large independent code model to achieve a score of 70+ on the HumanEval benchmark. Its training process is completely transparent, and the use of data and methods complies with laws and regulations.
In the field of independent controllable code large models, StarCoder2-15B-Instruct has significantly surpassed the previous leader OctoCoder, proving its leading position in this field.
Even compared to large and powerful models with restricted licenses such as Gemini Pro and Mistral Large, StarCoder2-15B-Instruct still shows excellent performance and is comparable to CodeLlama-70B-Instruct have equal shares. What is even more remarkable is that StarCoder2-15B-Instruct relies entirely on self-generated data for training, and its performance is comparable to OpenCodeInterpreter-SC2-15B based on GPT-3.5/4 data fine-tuning.
In addition to the EvalPlus benchmark test, StarCoder2-15B-Instruct has also shown strong strength on evaluation platforms such as LiveCodeBench and DS-1000.
LiveCodeBench focuses on evaluating coding challenges that will arise after September 1, 2023, and StarCoder2-15B-Instruct achieved the best results in this benchmark and always leads the usage OpenCodeInterpreter-SC2-15B fine-tuned on GPT-4 data Less, but its performance in this benchmark is still strong, showing broad adaptability and competitiveness.
##Breakthroughs and Enlightenments of StarCoder2-15B-Instruct-v0.1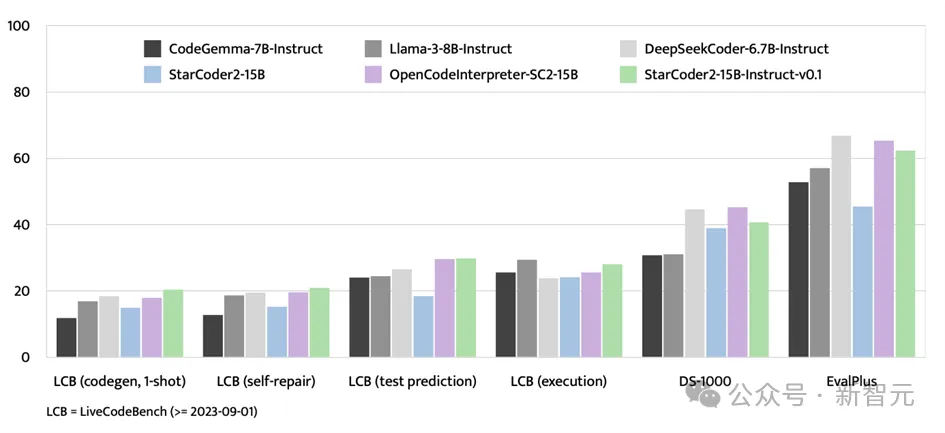
The release of StarCoder2-15B-Instruct-v0.1 marks an important step for researchers in the field of code model self-tuning. The successful practice of this model breaks the previous limitation of relying on powerful external teacher models such as GPT-4, and demonstrates that code models with excellent performance can also be built through self-tuning.
The core of StarCoder2-15B-Instruct-v0.1 lies in the successful application of its self-alignment strategy in the field of code learning. This strategy not only improves the performance of the model, but more importantly, it gives the model greater transparency and interpretability. This is in stark contrast to other large models such as Snowflake-Arctic, Grok-1, Mixtral-8x22B, DBRX, and CommandR+, which, while powerful, often limit their scope and trustworthiness due to a lack of transparency.
What’s even more gratifying is that StarCoder2-15B-Instruct-v0.1 has made its data set and entire training process-including data collection and training process-completely open source. This move not only demonstrates the open spirit of the researchers, but also lays a solid foundation for future research and development in this field.
There is reason to believe that the successful practice of StarCoder2-15B-Instruct-v0.1 will inspire more researchers to invest in research in the field of code model self-tuning and promote the development of this field. Technological progress and application expansion. At the same time, we also expect more innovative results in this field to continue to emerge, injecting new impetus into the intelligent development of human society.
##About the author
Teacher Zhang Lingming from UIUC is a scholar with profound attainments in the intersection of software engineering, programming language and machine learning. The research group he leads has long been committed to research on automatic software synthesis, repair and verification based on large AI models, as well as improving the reliability of machine learning systems.Recently, the team has released a number of innovative large code models and test benchmark data sets, and has taken the lead in proposing a series of large model-based software testing and repair technologies. At the same time, thousands of new defects and loopholes were successfully discovered in multiple real software systems, making significant contributions to improving software quality.
The above is the detailed content of No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undress AI Tool
Undress images for free

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to use PHP to build social sharing functions PHP sharing interface integration practice
Jul 25, 2025 pm 08:51 PM
How to use PHP to build social sharing functions PHP sharing interface integration practice
Jul 25, 2025 pm 08:51 PM
The core method of building social sharing functions in PHP is to dynamically generate sharing links that meet the requirements of each platform. 1. First get the current page or specified URL and article information; 2. Use urlencode to encode the parameters; 3. Splice and generate sharing links according to the protocols of each platform; 4. Display links on the front end for users to click and share; 5. Dynamically generate OG tags on the page to optimize sharing content display; 6. Be sure to escape user input to prevent XSS attacks. This method does not require complex authentication, has low maintenance costs, and is suitable for most content sharing needs.
 How to use PHP combined with AI to achieve text error correction PHP syntax detection and optimization
Jul 25, 2025 pm 08:57 PM
How to use PHP combined with AI to achieve text error correction PHP syntax detection and optimization
Jul 25, 2025 pm 08:57 PM
To realize text error correction and syntax optimization with AI, you need to follow the following steps: 1. Select a suitable AI model or API, such as Baidu, Tencent API or open source NLP library; 2. Call the API through PHP's curl or Guzzle and process the return results; 3. Display error correction information in the application and allow users to choose whether to adopt it; 4. Use php-l and PHP_CodeSniffer for syntax detection and code optimization; 5. Continuously collect feedback and update the model or rules to improve the effect. When choosing AIAPI, focus on evaluating accuracy, response speed, price and support for PHP. Code optimization should follow PSR specifications, use cache reasonably, avoid circular queries, review code regularly, and use X
 PHP calls AI intelligent voice assistant PHP voice interaction system construction
Jul 25, 2025 pm 08:45 PM
PHP calls AI intelligent voice assistant PHP voice interaction system construction
Jul 25, 2025 pm 08:45 PM
User voice input is captured and sent to the PHP backend through the MediaRecorder API of the front-end JavaScript; 2. PHP saves the audio as a temporary file and calls STTAPI (such as Google or Baidu voice recognition) to convert it into text; 3. PHP sends the text to an AI service (such as OpenAIGPT) to obtain intelligent reply; 4. PHP then calls TTSAPI (such as Baidu or Google voice synthesis) to convert the reply to a voice file; 5. PHP streams the voice file back to the front-end to play, completing interaction. The entire process is dominated by PHP to ensure seamless connection between all links.
 How to use PHP to combine AI to generate image. PHP automatically generates art works
Jul 25, 2025 pm 07:21 PM
How to use PHP to combine AI to generate image. PHP automatically generates art works
Jul 25, 2025 pm 07:21 PM
PHP does not directly perform AI image processing, but integrates through APIs, because it is good at web development rather than computing-intensive tasks. API integration can achieve professional division of labor, reduce costs, and improve efficiency; 2. Integrating key technologies include using Guzzle or cURL to send HTTP requests, JSON data encoding and decoding, API key security authentication, asynchronous queue processing time-consuming tasks, robust error handling and retry mechanism, image storage and display; 3. Common challenges include API cost out of control, uncontrollable generation results, poor user experience, security risks and difficult data management. The response strategies are setting user quotas and caches, providing propt guidance and multi-picture selection, asynchronous notifications and progress prompts, key environment variable storage and content audit, and cloud storage.
 PHP realizes commodity inventory management and monetization PHP inventory synchronization and alarm mechanism
Jul 25, 2025 pm 08:30 PM
PHP realizes commodity inventory management and monetization PHP inventory synchronization and alarm mechanism
Jul 25, 2025 pm 08:30 PM
PHP ensures inventory deduction atomicity through database transactions and FORUPDATE row locks to prevent high concurrent overselling; 2. Multi-platform inventory consistency depends on centralized management and event-driven synchronization, combining API/Webhook notifications and message queues to ensure reliable data transmission; 3. The alarm mechanism should set low inventory, zero/negative inventory, unsalable sales, replenishment cycles and abnormal fluctuations strategies in different scenarios, and select DingTalk, SMS or Email Responsible Persons according to the urgency, and the alarm information must be complete and clear to achieve business adaptation and rapid response.
 PHP integrated AI speech recognition and translator PHP meeting record automatic generation solution
Jul 25, 2025 pm 07:06 PM
PHP integrated AI speech recognition and translator PHP meeting record automatic generation solution
Jul 25, 2025 pm 07:06 PM
Select the appropriate AI voice recognition service and integrate PHPSDK; 2. Use PHP to call ffmpeg to convert recordings into API-required formats (such as wav); 3. Upload files to cloud storage and call API asynchronous recognition; 4. Analyze JSON results and organize text using NLP technology; 5. Generate Word or Markdown documents to complete the automation of meeting records. The entire process needs to ensure data encryption, access control and compliance to ensure privacy and security.
 How to build an online customer service robot with PHP. PHP intelligent customer service implementation technology
Jul 25, 2025 pm 06:57 PM
How to build an online customer service robot with PHP. PHP intelligent customer service implementation technology
Jul 25, 2025 pm 06:57 PM
PHP plays the role of connector and brain center in intelligent customer service, responsible for connecting front-end input, database storage and external AI services; 2. When implementing it, it is necessary to build a multi-layer architecture: the front-end receives user messages, the PHP back-end preprocesses and routes requests, first matches the local knowledge base, and misses, call external AI services such as OpenAI or Dialogflow to obtain intelligent reply; 3. Session management is written to MySQL and other databases by PHP to ensure context continuity; 4. Integrated AI services need to use Guzzle to send HTTP requests, safely store APIKeys, and do a good job of error handling and response analysis; 5. Database design must include sessions, messages, knowledge bases, and user tables, reasonably build indexes, ensure security and performance, and support robot memory
 How to use PHP to call AI writing auxiliary tools PHP improves content output efficiency
Jul 25, 2025 pm 08:18 PM
How to use PHP to call AI writing auxiliary tools PHP improves content output efficiency
Jul 25, 2025 pm 08:18 PM
When choosing an AI writing API, you need to examine stability, price, function matching and whether there is a free trial; 2. PHP uses Guzzle to send POST requests and uses json_decode to process the returned JSON data, pay attention to capturing exceptions and error codes; 3. Integrating AI content into the project requires an audit mechanism and supporting personalized customization; 4. Cache, asynchronous queue and current limiting technology can be used to optimize performance to avoid bottlenecks due to high concurrency.
